info@biz4group.com
info@biz4group.com 






































Imagine a digital system that doesn’t wait for instructions but instead, understands your business goals, learns from real-time feedback, and takes independent actions to get the job done.
Read More

AI, now, is a force shaping market leaders. 78% of organizations now use AI in at least one business function, with enterprise adoption surging across sectors and use cases. That means companies that fail to understand open source LLMs risk falling behind businesses who already leverage them for automation, insight, and innovation.
Open source LLMs have moved past experimentation. Enterprises today are exploring the best open source LLM models not only to cut costs but to secure full control over their AI stack. For building internal assistants, customer support bots, or analytics tools, leaders are choosing top open source large language models to unlock real outcomes.
What makes this moment so exciting is the pace of change. New releases and breakthroughs arrive every few months. This means early adopters of open source LLM options for businesses are already seeing measurable advantages in performance, flexibility, and operational cost.
Our goal in this guide is to cut through the noise and help you confidently compare open source LLM tools and choose the models that match your business needs. In the sections ahead, you will find clear comparisons and effective ready-to-deploy strategies.
If improving product innovation and AI adoption matters to you, keep reading.
Companies exploring open source LLMs often want clarity on which models deliver reliable performance and sustainable value. With so many choices in the market, it can feel overwhelming to separate hype from actual impact.
A high value model does more than generate text. It strengthens product capabilities, lowers development costs, and gives teams better control over how their systems behave. To help simplify your evaluation, here is a structured view of the qualities that define the best open source LLM models for enterprise use.
Businesses tend to look for some traits when comparing options. Each of these qualities determines how well a model supports growth, long term AI adoption, and operational stability.
Here is a concise table that outlines what separates promising models from weaker candidates.
|
Evaluation Area |
Why It Matters |
What Businesses Should Look For |
|---|---|---|
|
Licensing |
Determines how the model is used in products |
Open, permissive and easy to interpret terms |
|
Performance |
Affects latency and output quality |
Consistency across reasoning, writing and task execution |
|
Training Flexibility |
Influences adaptation to your domain |
Support for adapters, fine tuning and lightweight customization |
|
Deployment Fit |
Drives cost and scalability |
Cloud, on prem or hybrid options with simple orchestration |
|
Tooling Ecosystem |
Impacts speed of development |
Libraries, integrations and active community input |
Companies that thrive with top open source large language models evaluate not only accuracy but how quickly the model can be maintained, improved and integrated with product workflows. Once these fundamentals are clear, comparing choices becomes much easier.
Also read: NLP vs LLM: Choosing the right approach for your AI strategy
The landscape of open source LLMs has changed rapidly. What once looked like a scattered collection of research experiments has matured into a powerful ecosystem of enterprise ready AI engines.
With tech teams increasingly moving from prototype to production, organizations want clarity on how each model performs and which ones deliver dependable long term value.
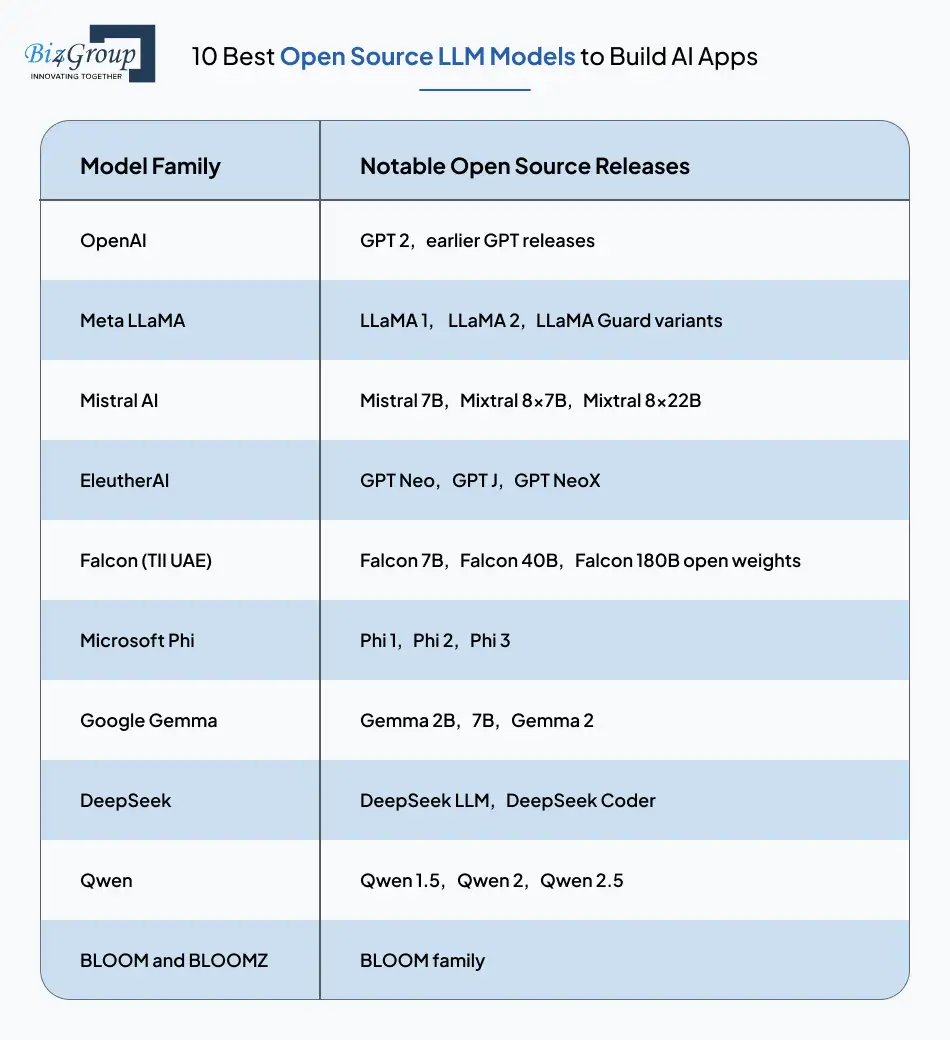
To help readers get oriented, here is a quick comparison table that highlights the essential aspects of the most influential top open source large language models available today.
|
Model Family |
Notable Open Source Releases |
License Type |
Typical Sizes |
|---|---|---|---|
|
OpenAI |
GPT 2, earlier GPT releases |
Open source (varies by version) |
Up to 1.5B |
|
Meta LLaMA |
LLaMA 1, LLaMA 2, LLaMA 3, LLaMA Guard variants |
Community licenses |
7B to 70B |
|
Mistral AI |
Mistral 7B, Mixtral 8x7B, Mixtral 8x22B |
Apache 2.0 or similar permissive licenses |
7B to MoE architectures |
|
EleutherAI |
GPT Neo, GPT J, GPT NeoX |
Permissive open licenses |
1.3B to 20B |
|
Falcon (TII UAE) |
Falcon 7B, Falcon 40B, Falcon 180B open weights |
Varies. Falcon 180B is non commercial |
7B to 180B |
|
Microsoft Phi |
Phi 1, Phi 2, Phi 3 |
MIT style for early versions |
1B to 14B |
|
Google Gemma |
Gemma 2B, 7B, Gemma 2 |
Apache 2.0 |
2B to 27B |
|
DeepSeek |
DeepSeek LLM, DeepSeek Coder |
Open weights releases |
Various sizes |
|
Qwen |
Qwen 1.5, Qwen 2, Qwen 2.5 |
Apache 2.0 |
0.5B to 72B |
|
BLOOM and BLOOMZ |
BLOOM family |
BigScience open license |
176B |
A helpful starting point is now in place. You have a bird eye view that captures how the leading open source LLM options for businesses stack up.
OpenAI shaped the public understanding of language models long before enterprise AI became mainstream. While modern OpenAI models are not open source, the organization released earlier generations like GPT 2 under open licenses. GPT 2 offered strong generation quality relative to its time and helped establish the foundation for many open research projects.
Key Differentiators
Use Cases
Training Data Notes
GPT 2 was trained on a large public dataset sourced from web content. OpenAI released both model weights and code.
Strengths
Meta advanced the open source landscape through the LLaMA line, which offered accessible model weights and performance suitable for a wide range of enterprise workloads. LLaMA 1, LLaMA 2 and LLaMA 3 families contributed to a more transparent and collaborative ecosystem. LLaMA Guard enhanced safety focused filtering.
Key Differentiators
Use Cases
Training Data Notes
Models were trained on curated web sources, publicly available texts and filtered datasets to improve quality.
Strengths
Mistral gained attention for compact, efficient models and mixture of experts designs that delivered high quality outputs with lower resource needs. Mistral 7B, Mixtral 8x7B and Mixtral 8x22B provided competitive performance with open and permissive licensing, making them popular in production systems.
Key Differentiators
Use Cases
Training Data Notes
Models were trained on licensed sources and filtered web content with attention to data quality.
Strengths
EleutherAI played a foundational role in democratizing large model research. Their releases helped spark the wave of open innovation that followed. GPT Neo, GPT J and GPT NeoX provided accessible alternatives to early proprietary systems and invited widespread experimentation.
Key Differentiators
Use Cases
Training Data Notes
Models were trained on The Pile, a diverse and openly documented dataset.
Strengths
If open research communities can reshape the industry this fast, imagine what your business could do with the right development team behind it.
Build with Biz4GroupFalcon made a significant impact with high performing open weight releases that gained traction across large organizations. Falcon 7B and Falcon 40B provided competitive results. Falcon 180B was released with open weights but not for commercial use.
Key Differentiators
Use Cases
Training Data Notes
Models were trained on RefinedWeb, a filtered set of high quality web sources.
Strengths
The Phi family demonstrated that small models can deliver strong performance when trained on carefully curated datasets. Phi 1, Phi 2 and Phi 3 earned recognition for their compact sizes and impressive reasoning ability relative to their parameter counts.
Key Differentiators
Use Cases
Training Data Notes
Models were trained on educational texts and curated synthetic data designed to improve reasoning.
Strengths
Google entered the open source space with Gemma, a family focused on responsible development and accessible performance. Gemma 2B and 7B received positive feedback for their clean architecture. Gemma 2 introduced larger sizes that improved reasoning and grounding.
Key Differentiators
Use Cases
Training Data Notes
Sources included web texts, multilingual corpora and safety reviewed datasets.
Strengths
DeepSeek gained traction for strong reasoning and coding focused capabilities. DeepSeek LLM and DeepSeek Coder models delivered practical improvements for development workflows and logic-heavy tasks.
Key Differentiators
Use Cases
Training Data Notes
Models were trained on code datasets and general text sources.
Strengths
Qwen models set a high bar for multilingual performance and broad domain coverage. Qwen 1.5, Qwen 2 and Qwen 2.5 provided a wide range of parameter sizes and open commercial friendly licensing.
Key Differentiators
Use Cases
Training Data Notes
Models were trained on multilingual web content, licensed data and domain balanced corpora.
Strengths
BLOOM represented one of the largest collaborative efforts in open model development with contributions from global institutions. BLOOM and BLOOMZ were designed to support a wide multilingual dataset and encourage transparent research across communities.
Key Differentiators
Use Cases
Training Data Notes
Models were trained on a multilingual dataset curated by the BigScience project.
Strengths
You have now explored a wide spectrum of open source LLMs that continue to shape real progress for companies building modern AI features. This overview sets the stage for a more focused approach where business priorities guide the choice of model.
Comparing models takes minutes. Turning them into revenue generating products takes expertise.
Get in Touch and Leverage Our ExperienceSelecting the right model is not about chasing the largest parameter count or picking the one that receives the most online attention. The focus shifts to which model supports your daily operations and long-term plans.
Teams that succeed with open source LLMs think about cost control, data sensitivity, user experience, scaling patterns and domain requirements.
A simple first step is to understand the nature of your use case. Some applications need speed. Others need depth. Some need multilingual support. Others need predictable reasoning. With that context in mind, the evaluation becomes more structured.
These factors steer you away from a one-size-fits-all mindset and toward a solution that feels engineered for your team rather than borrowed from another company’s roadmap.
The table below offers a quick view of how different priorities align with model families.
|
Business Priority |
Recommended Model Families |
Why They Fit Well |
|---|---|---|
|
Fast and efficient responses |
Mistral, Phi |
Strong runtime efficiency and low hardware demand |
|
Global multilingual reach |
Qwen, Gemma, BLOOM |
Wide language coverage for customer facing tools |
|
Coding and technical tasks |
DeepSeek |
Strong coding and reasoning orientation |
|
Enterprise assistants and copilots |
LLaMA, Mistral |
Balanced performance and broad community support |
|
Academic or research labs |
EleutherAI, BLOOM |
Fully open training process and transparent design |
|
Lightweight experimentation and training |
OpenAI early releases, EleutherAI |
Smaller sizes that support rapid prototyping |
Instead of starting with benchmarks alone, begin with your end users.
What do they expect from your product? Speed? Depth? Accuracy? Domain understanding?
These qualities differ from case to case. For example, a customer service assistant benefits from multilingual fluency, while a developer tool needs consistent reasoning. A retail knowledge system might depend on structured retrieval rather than generative ability.
Here is a simple framework that many leaders find helpful.
Teams that take a structured approach rarely feel overwhelmed by the number of top open source large language models available today. Instead, they focus on the model that aligns with their context, resources and product direction. This clarity leads to faster creation of prototypes and more stable production rollouts.
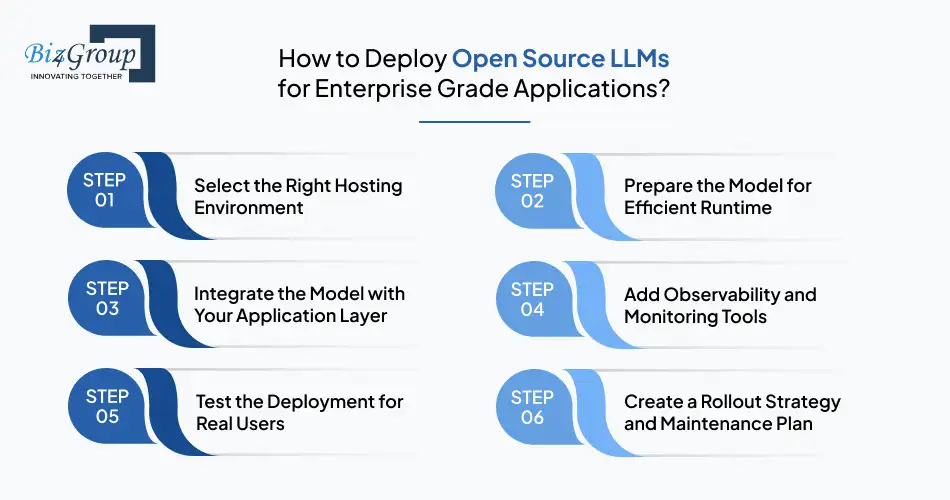
Deploying open source LLMs can feel like a large undertaking at first glance, but once the steps are broken down, the process becomes smooth and predictable. The goal is not only to run a model but to build a setup that scales, stays compliant, and supports your AI product vision without uncontrolled cost growth.
The heart of deployment is understanding how your users interact with the system. Once the behavior is mapped, choosing hosting, optimization and monitoring paths becomes much easier.
Different businesses choose different hosting models. Each path carries benefits depending on your needs.
Options to consider:
|
Hosting Path |
Best For |
Notes |
|---|---|---|
|
Cloud |
Fast rollout and elastic scaling |
Ideal for growing applications with variable traffic |
|
On premises |
Sensitive data or strict compliance |
Greater control and security requirements |
|
Hybrid |
Balanced performance and privacy |
Common for enterprise platforms |
|
Containerized setups |
Flexible engineering workflows |
Works well with orchestrators and microservices |
A short internal review of data flows helps you choose the most stable hosting strategy.
Once hosting is selected, the next step is to shape your model for production behavior. This helps reduce resource usage and improves response times.
Key preparation tasks:
These adjustments improve consistency for both user facing apps and backend systems.
The bridging process connects your model to your product features. During this step, teams decide how the model will interpret input, return output and interact with other services.
Integration examples:
Using top-notch AI integration services ultimately determines how smooth your entire workflow feels for end users.
Production setups benefit from complete visibility into how models behave. Monitoring improves stability and helps product teams understand how real users interact with the system. Track latency, error patterns, token usage, request spikes, and output consistency.
Useful monitoring layers:
|
Monitoring Area |
Why It Matters |
|---|---|
|
Performance |
Helps keep response times steady |
|
Quality checks |
Identifies drift or unusual outputs |
|
Usage audits |
Supports resource planning and budgeting |
Strong observability gives your team confidence during scaling periods.
Testing goes beyond traditional QA. For top open source large language models, the focus is on understanding how the system performs under different scenarios and user expectations.
Practical testing methods:
These tests bring clarity to how your deployment performs across varied contexts.
Once testing looks solid, the final step is to prepare a rollout path that avoids disruption and allows gradual growth.
Rollout considerations:
A thoughtful rollout keeps user trust intact and gives your team enough room to tune the system.
Companies that follow a step-by-step deployment approach are able to bring open source LLMs into production with fewer surprises and more predictable outcomes. This creates a stable foundation for both innovation and long-term maintenance.
Also read: An enterprise guide to AI model development from scratch
Most companies lose weeks fine tuning infrastructure decisions. Our clients cut that time by more than 40% with guided deployment planning.
Schedule a Free Call Today
Managing cost is one of the most important parts of deploying open source LLMs at scale. Teams often focus on accuracy and speed while overlooking the financial footprint. A thoughtful cost plan influences product margins, infrastructure choices and growth.
When businesses adopt the best open source LLM models, expenses tend to fall under four main buckets. Getting clear on each one helps you organize a realistic project budget.
Key Cost Buckets:
Each of these areas has predictable patterns that can be optimized.
Hosting prices depend on model size and environment. Companies often split into two groups of cloud users and on premises users. Here is a general view:
|
Model Size |
Typical Cloud VM Cost per Month |
Typical On Prem Cost Estimate |
|---|---|---|
|
7B to 13B |
400 to 1600 USD |
8,000 to 15,000 USD for a single GPU server |
|
30B to 70B |
1800 to 4200 USD |
20,000 to 40,000 USD for multi GPU setups |
|
Mixture of Experts |
2500 to 6000 USD |
40,000 USD and above depending on card count |
Cloud costs scale with usage hours. On premises costs reflect one-time hardware purchases along with power and cooling overhead.
Inference usually makes up the highest recurring expense. Teams need to estimate request volume and latency requirements to choose the best configuration.
Typical compute costs:
Businesses that optimize batching and caching can reduce this cost by 25-45% without affecting user experience.
Fine tuning creates measurable improvements, but it carries training expenses. Smaller models allow lighter customization with modest budgets, while larger models require more compute.
|
Model Size |
Fine Tuning Cost Range |
Notes |
|---|---|---|
|
Under 10B |
1,500 to 6,000 USD |
Can run on a few A100 hours |
|
10B to 30B |
8,000 to 20,000 USD |
Requires multi GPU setups |
|
Over 30B |
25,000 to 60,000 USD |
Used by enterprises with complex domains |
Efficient training strategies such as LoRA and QLoRA can cut these costs by 40-70% while still improving model behavior.
These costs tend to scale gradually, but they are still important to budget for.
Teams that set clear retention policies and routing rules often lower these costs by 15-30%.
Startups usually begin with smaller or mid-sized top open source large language models that deliver good accuracy without heavy hardware demands.
Common Startup Strategies
These steps can reduce monthly spend to under 3,000 USD for many early-stage products.
Large organizations work at higher traffic levels, which changes the economics. Cost efficiency becomes a function of scaling and automation.
Enterprise Approaches
Enterprises often operate within 20,000 to 120,000 USD per month, depending on volume and compliance needs.
Companies that take a structured approach to cost planning find that open source LLM options for businesses offer predictable expenses and meaningful savings. With smart optimization, teams often reduce compute spending by a wide margin while still achieving strong performance.
Security plays a central role when companies adopt open source LLMs for real-world applications. Enterprises hold sensitive customer data, internal records and intellectual assets that must be handled with caution. A strong governance plan keeps deployments stable and reduces operational risk.
Security begins with understanding how data travels across your pipeline. Teams take time to document paths, classify data and identify high risk touchpoints.
Key elements:
These steps form the foundation that every other control builds upon.
Compliance rules vary across industries. Businesses using top open source large language models adopt guidelines that apply to their region and customer base.
Common frameworks:
Governance plans keep models predictable and aligned with business standards. They also ensure your systems behave consistently as user volume grows.
Helpful governance measures:
Every production model carries some risk if not monitored properly. The key is to identify issues early and build guardrails that reduce their impact.
Risk mitigation table:
|
Risk Type |
Example Impact |
Helpful Control |
|---|---|---|
|
Data exposure |
Leaking private fields |
Prompt sanitization, input filtering |
|
Output inconsistency |
Confusing user experience |
Response validation rules |
|
Bias issues |
Uneven performance across groups |
Fairness evaluation cycles |
|
Prompt manipulation |
Unwanted behavior |
Safety checks and restricted system prompts |
Security and governance become ongoing commitments that scale with your platform. Teams that stay proactive avoid disruption and maintain user trust even as their models grow more capable.
Businesses that adopt structured governance outperform others in long term stability.
Talk to Our Experts
The next wave of progress in open source LLMs is already taking shape, and the pace of improvement continues to accelerate. These trends help companies plan their AI strategy with clarity.
Models that blend generation with structured retrieval will rise in popularity. These systems reduce hallucinations and improve factual grounding. Enterprises benefit from tighter control of knowledge and lower compute usage.
More organizations will adopt industry-focused versions of best open source LLM models. Finance, healthcare, retail and legal sectors will see rapid development of targeted models that understand terminology and workflows. This saves companies time during integration.
Global platforms need consistent output across languages. Future open source families will expand language coverage and improve regional accuracy. This supports cross border SaaS products and customer support operations.
Companies with sensitive data will adopt local hosting more frequently. Advances in quantization and optimization allow large models to run efficiently on controlled hardware. This helps teams balance privacy with performance.
Products will use more than one model at a time. Routing systems will choose the best model based on user intent, cost or latency. This creates higher quality experiences without raising compute budgets.
Development frameworks will grow more stable. Integrations will become easier and monitoring pipelines will expand. This gives engineering teams predictable workflows and faster release cycles.
Open source projects will attract more contributions from commercial players. Companies will sponsor improvements, share benchmarks and participate in model evaluations that raise overall quality for the ecosystem.
These trends create a future where companies gain more control, more efficiency and more customization when adopting open source LLM options for businesses.
In the United States, Biz4Group LLC stands out as a trusted partner for businesses seeking real results from open source LLMs. We are a custom software development company built around the purpose of empowering organizations with scalable, secure and cost-efficient enterprise AI solutions.
Our teams work across UI/UX design, engineering, strategy and deployment. This gives our clients a complete journey from concept to production.
Companies choose Biz4Group LLC because we combine technical depth with business clarity. Our work spans cloud, on premises, hybrid and privacy focused deployments so organizations get the environment that matches their compliance needs.
What makes us a preferred partner is our ability to merge open source LLM options for businesses with commercial grade reliability. Many companies struggle to decide between proprietary tools and open source frameworks. Our strength lies in guiding them through this choice and building systems that deliver measurable value from day one.
To demonstrate that, here are two of our standout projects.
As a trusted AI chatbot development company, we built customer service AI chatbot to redefine customer interactions for growing enterprises. Support teams faced long handling times, high workloads and inconsistent resolutions. Our solution was a production ready AI assistant trained on large volumes of customer interactions and refined for support tasks.
Results Achieved
Key Strengths of the Platform
Security and Deployment Advantages
The system helped multiple clients scale from high volume queues to automated workflows that run day and night. This project showed how well tuned open source LLM frameworks can outperform traditional support tools and cut overhead costs for every department involved.
As an agentic AI development company, we built an enterprise AI agent that offers intelligent automation with strict data controls. The solution serves healthcare networks, financial services providers, and HR departments that handle sensitive information every day.
Key Capabilities
Challenges We Faced
How We Solved Them
This project reaffirmed the value of pairing open source LLM engines with a robust compliance mindset. Companies gained the speed of automation without risking their privacy commitments, and employees experienced faster, more dependable support responses.
Both projects highlight a simple idea. Businesses do not need to choose between innovation and stability. With the right engineering partner, they get both. Open source LLMs provide flexibility and ownership. Biz4Group provides the design thinking, technical precision and deployment maturity to turn these models into dependable enterprise tools.
So, without any further delay, get in touch with us today.
Open source LLMs have become a dependable foundation for modern business innovation. They give companies the freedom to shape their own AI systems, control their data and reduce the dependency on locked platforms. With a wide range of strong model families available, organizations can compare performance, evaluate costs and choose the models that match their product vision with real clarity.
As the ecosystem continues to grow, businesses gain remarkable flexibility. Smaller models become more capable, large models become more efficient, and deployment options expand across cloud, hybrid and private environments.
Biz4Group LLC, with our AI development services, play an active role in helping enterprises turn these models into working solutions. Our team understands both the technology and the business goals behind it. We combine open source LLM capabilities with secure engineering, AI automation services and production ready deployments so organizations can adopt AI without friction or uncertainty.
If your business is exploring its next AI step, this is the right moment to start. Connect with Biz4Group LLC, hire AI developers, and let us help you build an AI solution that gives you an advantage in your market. We are ready when you are.
Yes. Many organizations in healthcare, finance and legal fields adopt open source models because they can host them in secure environments and apply their own compliance controls. This allows teams to meet industry standards while keeping full control of sensitive data.
Smaller teams often benefit from open source models because they can start with compact versions, add selective customization and avoid expensive usage fees. This creates a practical entry point for startups building new AI features.
A simple approach is to test models on tasks that mirror your real user interactions. Many companies create small evaluation sets that represent their domain and measure accuracy, response style and consistency under expected workloads.
Yes. Many organizations adjust model behavior using prompt templates, routing logic, retrieval systems or lightweight adapters. These methods offer control without the need for full training cycles.
For low volume or periodic workloads, companies often rely on shared cloud instances or small GPU nodes. This allows them to pay only for usage time instead of maintaining dedicated hardware.

with Biz4Group today!
Our website require some cookies to function properly. Read our privacy policy to know more.