info@biz4group.com
info@biz4group.com 






































Imagine a digital system that doesn’t wait for instructions but instead, understands your business goals, learns from real-time feedback, and takes independent actions to get the job done.
Read More

Imagine if every piece of written content your business creates could instantly speak to your audience in a human voice, that too without hiring voice talent or recording studios. That’s no longer a future dream; it’s the reality being driven by text to speech app development with AI across modern digital products.
The global Text-to-Speech market continues to expand rapidly as enterprises and digital products prioritize voice-enabled experiences. According to industry analysis, the text-to-speech market was valued at around USD 4.66 billion in 2025 and is on track to reach USD 7.6 billion by 2029, expanding at a CAGR of 13.7% thanks to advancements in neural speech synthesis and AI-driven voice technology.
AI text-to-speech is becoming a core capability inside modern digital products, driven by AI automation needs, accessibility requirements, and rising expectations for voice-enabled experiences. Built within broader enterprise AI solutions, voice experiences are quickly becoming a competitive differentiator. This space is moving fast, and someone is going to set the standard. It might as well be the team reading this.
This guide shows you exactly how to do that. We’ll break down the strategy behind AI text-to-speech apps, the features that matter, the technology choices involved, and the roadblocks teams commonly face.
An AI text-to-speech application converts written text into natural, human-like speech that can be embedded directly into digital products. Unlike traditional TTS systems that depend on rigid rules or recorded audio clips, modern AI text-to-speech apps rely on neural models to generate speech dynamically. This makes them far more adaptable, scalable, and suitable for enterprise-grade applications.
Teams that develop AI text to speech application solutions typically expose text-to-speech functionality through APIs or backend services and integrate it into web apps, mobile apps, or enterprise platforms. Most modern solutions are built using generative AI solutions, where speech models are trained on large datasets to understand pronunciation, pacing, and contextual emphasis. It forms the foundation of AI voice technology application development using text. This allows teams to build AI-powered text-to-speech apps that support multiple languages, accents, and voice styles without manual voice recording.
The working of an AI text-to-speech application typically follows a structured pipeline:
When implemented correctly, AI text-to-speech app development delivers reliable, production-ready voice capabilities that integrate smoothly into modern digital products without adding unnecessary complexity.
Also Read: How to Build a Speech Recognition System With AI?
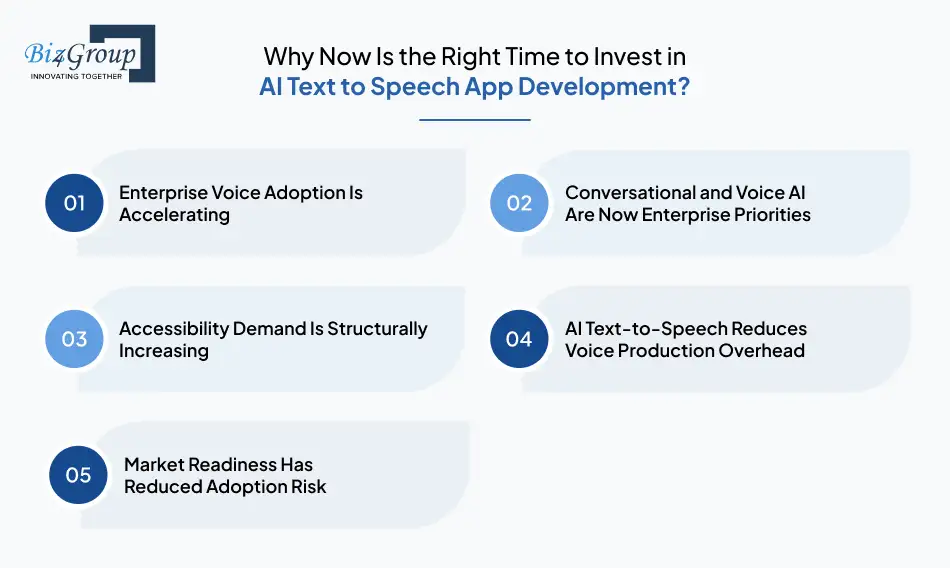
Voice is becoming part of how digital products actually function. As enterprises scale content, support, and accessibility, AI text to speech app development is shifting from an optional enhancement to a practical business investment.
AI text to speech app development is increasingly becoming part of mainstream business app development, especially for customer support platforms, SaaS products, and content-heavy applications where scalable voice output is critical.
A Gartner survey reveals that a large majority of customer service leaders are actively exploring or piloting conversational and voice-based AI solutions, signaling strong enterprise momentum toward speech-driven interfaces.
According to the WHO Report, more than 2.2 billion people worldwide live with visual or reading impairments. This makes AI text to speech applications essential for accessible digital experiences across healthcare, education, and enterprise platforms, especially for teams looking to build AI speech synthesis app for eLearning and media at scale.
Businesses building AI powered text to speech apps for businesses are replacing manual voice recording with automated speech synthesis, enabling faster content updates, consistent voice quality, and lower operational costs at scale.
As AI text to speech technology matures, organizations now have clearer implementation paths, proven use cases, and access to expert AI consulting services that help deploy voice solutions securely and sustainably.
AI text to speech app development is moving from early adoption to real-world use. Enterprises that invest now gain practical advantages in accessibility, automation, and voice scalability before these capabilities become baseline expectations in digital products.
To deliver reliable and scalable voice experiences and develop AI text to speech app for enterprise use, it must be built on a solid functional foundation. For organizations investing in AI text to speech app development, these capabilities form the baseline required to ensure voice output is consistent, accurate, and ready for enterprise deployment.
The foundation of any AI text-to-speech application is voice quality. Modern apps rely on neural speech synthesis to produce clear, expressive, and natural-sounding speech that avoids robotic tones and flat delivery. This directly impacts user trust and adoption.
To serve global audiences, AI text to speech apps must support multiple languages, accents, and regional pronunciations. This feature is critical for SaaS platforms, media companies, and enterprises operating across markets.
A reliable AI text-to-speech app should handle both:
This flexibility supports customer support, content publishing, and enterprise workflows.
Core controls such as speed, pitch, pauses, and emphasis allow teams to fine-tune voice output for different use cases. Accurate pronunciation handling is especially important for industry terms, names, and abbreviations.
Voice output must align with how users interact with the product. Effective AI assistant app design ensures that speech delivery feels intuitive, accessible, and consistent across platforms.
To support scalable deployment, AI text to speech app is typically delivered through API development. This allows businesses to integrate voice generation into existing products, workflows, and enterprise systems without rebuilding their architecture.
These features can be summarized as core functional requirements below:
|
Feature |
Core Value |
|---|---|
|
Natural Voice Output |
Human-like, expressive speech that builds trust |
|
Multi-Language & Accents |
Global language and regional pronunciation support |
|
Real-Time & Batch Processing |
Instant output and large-scale audio generation |
|
Speech Controls |
Fine-tuned control over pronunciation, speed, and tone |
|
Voice-First UX |
Intuitive, accessible voice interactions |
|
API Integration |
Easy integration into existing systems |
Also Read: Adopt an API-First architecture for business agility
These core features define whether an AI text-to-speech app is usable, scalable, and enterprise-ready. Without a strong foundation in AI model development, even advanced voice systems fail to deliver real product value. Ddeliver real product value.
Define the voice capabilities that actually improve usability and adoption.
Refine TTS FeaturesOnce the core foundation is in place, advanced capabilities help businesses push AI text-to-speech beyond basic voice output and into differentiated, high-impact product experiences. These features are especially relevant for organizations planning custom AI text to speech app development for enterprise-scale use, personalization, and complex interaction scenarios.
Context-aware voice delivery goes beyond static speech output. By analyzing intent and emotional signals within text, AI sentiment analysis enables dynamic adjustments to tone, pacing, and emphasis, making voice interactions suitable for customer support, healthcare, and media use cases.
Businesses increasingly want voices that align with their brand identity, especially when they aim to create AI voice generation app from text for consistent, scalable voice experiences.
The custom AI voice changer app allows teams to create unique, consistent voice personas instead of relying on generic presets, an important step when you build AI powered text to speech apps for businesses.
Advanced systems analyze surrounding text and usage context to improve pronunciation, pacing, and emphasis. This capability is essential when developing neural text-to-speech systems for industry-specific content, technical terminology, or dynamic data.
AI text-to-speech becomes significantly more powerful when paired with conversational workflows, especially for teams looking to create an AI driven voice assistant app from text that responds intelligently in real time. Integration with AI conversation app logic allows voice output to respond dynamically in real time, enabling richer voice-driven interactions.
For customer-facing products, advanced AI TTS is often combined with chatbot systems to deliver end-to-end voice experiences. Support for AI chatbot integration ensures smooth handoffs between text, logic, and speech layers.
Advanced features transform AI text-to-speech from a utility into a strategic product capability. For teams aiming to create scalable, intelligent voice experiences, these enhancements unlock personalization, brand control, and deeper user engagement.
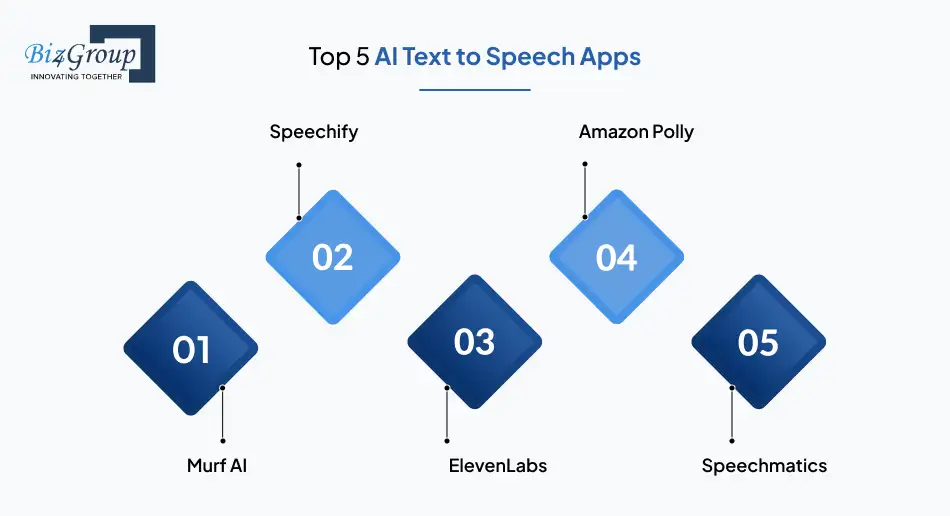
These platforms demonstrate how modern AI text to speech app development translates into production-ready solutions. Each one reflects how core capabilities and advanced features are already being applied in real business environments.
Murf AI is widely used for professional voice generation in business content, training modules, and media workflows. It focuses on producing controlled, natural-sounding speech that works reliably across structured and long-form text input. The app is equipped with
Also Read: AI Voice Generator Platform Development like Murf AI: Business Model, Steps and Cost
Speechify is built for fast, real-time AI text-to-speech delivery, especially for accessibility and content consumption use cases. It prioritizes clarity, speed, and cross-device usability for users who rely on spoken content daily. The app offers
It is known for advanced neural text-to-speech with a strong focus on expressiveness. Its technology enables emotionally rich, natural speech that closely mirrors human voice patterns in dynamic and conversational scenarios. ElevenLabs has:
Also Read: Top ElevenLabs Alternatives
This enterprise-grade AI text-to-speech service is designed for large-scale deployment. It supports both real-time and batch processing and integrates seamlessly into existing applications through robust APIs. It equips you with:
Speechmatics focuses on accuracy-driven speech technologies, supporting complex vocabulary and contextual understanding. It is often adopted in environments where pronunciation precision and consistency are critical. It offers:
Together, these platforms confirm what modern AI text-to-speech apps must deliver natural voice quality, control, scalability, and intelligent speech handling. Reinforcing these core and advanced features should be prioritized by businesses when building AI text-to-speech applications.
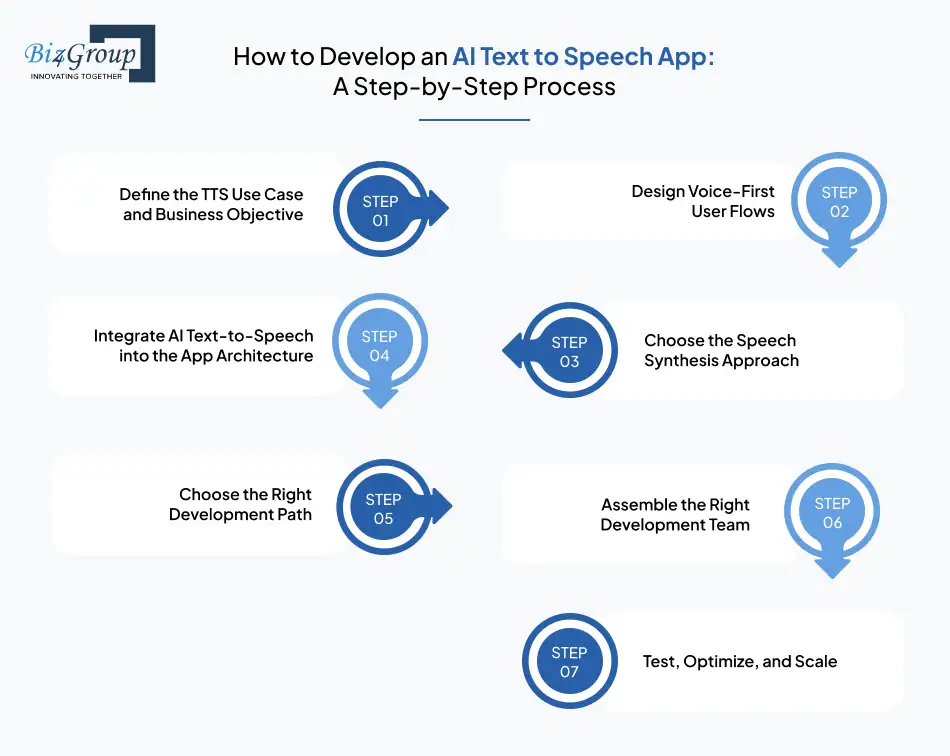
Developing an AI text-to-speech application is a structured product exercise, not a plug-and-play task. Each step below focuses on decisions that directly affect voice quality, scalability, accessibility, and long-term usability in AI text to speech app development.
Every successful AI text-to-speech app starts with clarity on why voice is being introduced and where it delivers value. This step ensures that the solution is aligned with real product goals rather than experimental adoption.
Clear use-case definition helps teams develop AI text to speech applications that are purpose-driven, measurable, and easier to scale without rework later.
Voice output must feel like a natural extension of the product experience. This step focuses on designing interactions where AI text-to-speech improves usability instead of interrupting workflows.
The voice-first UX design reduces friction and increases adoption when teams build AI-powered text to speech apps for real users. Therefore, strong UI/UX design company ensures AI text-to-speech enhances clarity and engagement across devices. ensures AI text-to-speech enhances clarity and engagement across devices.
Also Read: Top UI/UX Design Companies in USA
At this stage, teams decide how speech will be generated and controlled within the app. These choices directly influence voice realism, flexibility, and long-term customization options. You should:
Choosing the right approach early makes it easier to develop neural text to speech systems that balance quality, performance, and cost.
AI text-to-speech must integrate cleanly with existing systems to perform reliably at scale. This step focuses on embedding voice generation without disrupting core application logic.
A structured approach to AI integration into an app ensures the speech layer remains stable under production workloads. Well-planned integration is critical when teams aim to build AI speech synthesis applications for enterprise use.
Before full-scale deployment, teams should validate assumptions through a focused MVP. This step reduces risk and provides early feedback on voice performance and user acceptance.
An MVP-first approach aligns well with proven MVP development strategies for AI-driven products. Early validation ensures resources are invested in features that genuinely improve the AI text-to-speech experience.
Also Read: Top 12+ MVP Development Companies to Launch Your Startup
AI text-to-speech app development requires expertise beyond standard app engineering. This step focuses on building or sourcing the right skill set to execute efficiently.
The right team directly impacts how fast and reliably you can build AI-powered text to speech apps for businesses. Many organizations choose to hire AI developers with prior speech-based project experience to accelerate delivery and reduce technical risk
After validation, the focus shifts to stability and scale. This step ensures that the AI text-to-speech app performs consistently as usage grows across users, regions, and workloads.
Many teams also collaborate with specialized software testing company to validate performance, accuracy, and scalability before wider rollout.
A structured, step-by-step approach helps businesses build AI text-to-speech apps that are scalable, accurate, and production-ready. When each phase is handled deliberately, voice becomes a reliable product of capability, not a fragile add-on.
Turn a structured TTS roadmap into a dependable, production-ready app.
Build Your AI TTS RoadmapAn AI text-to-speech app requires a technology stack that supports scalable app development while handling speech-specific processing and voice generation. Many businesses partner with a custom software development company to architect this balance effectively.
Here’s a breakdown of the essential tools and technologies required for the development of AI text to speech app:
|
Layer |
Technologies Used |
Role in AI Text to Speech App |
|---|---|---|
|
Frontend (Web / App) |
React JS, Next.js |
React JS development enables component-based UI development for text input, voice controls, and accessibility features, while Next JS development adds server-side rendering, routing, and performance optimization for scalable, SEO-friendly AI TTS interfaces. |
|
Audio Playback Layer |
Web Audio API, HTML5 Audio |
Handles speech playback, pause/resume, speed control, and synchronization between text and audio |
|
Backend Services |
Node.js, Python |
NodeJS development handles asynchronous API requests, real-time processing, and scalable service orchestration, while Python development manages AI model interaction, text preprocessing, and speech generation workflows. |
|
API Frameworks |
Express.js, FastAPI |
Exposes secure endpoints for real-time and batch text-to-speech processing |
|
Text Processing |
Text normalization, tokenization |
Converts raw text into speech-ready format (numbers, abbreviations, symbols) |
|
Pronunciation Engine |
Grapheme-to-Phoneme (G2P) models |
Ensures accurate pronunciation across languages, accents, and domain terms |
|
Prosody Control |
SSML support, prosody modeling |
Controls pitch, pauses, emphasis, and speaking rate in generated speech |
|
Speech Synthesis Engine |
Neural TTS models |
Generates natural, human-like voice output from processed text |
|
Inference & Model Serving |
Speech inference servers |
Enables real-time and batch speech generation at scale |
|
Audio post-processing |
Audio formatting, sampling, compression |
Optimizes speech output for playback quality and device compatibility |
|
Database |
MongoDB, PostgreSQL |
Stores user settings, voice preferences, text input, and usage metadata |
|
Audio Storage |
Cloud object storage |
Stores generated speech files for reuse, streaming, and batch delivery |
|
Caching Layer |
Redis |
Reduces latency and cost by caching frequently requested speech outputs |
|
Security |
OAuth 2.0, JWT, API gateways |
Secures speech APIs and protects text and voice data |
|
DevOps & Deployment |
Docker, Kubernetes |
Enables scalable, containerized deployment of TTS services |
|
Cloud Infrastructure |
AWS, Azure, GCP |
Provides compute power, global availability, and reliability for speech workloads |
|
Monitoring & Analytics |
Performance monitoring tools |
Tracks latency, speech accuracy, failures, and system health |
A well-designed technology stack is critical for delivering reliable AI text-to-speech experiences. Since these apps span frontend, backend, and speech processing, strong full stack development expertise helps ensure performance, scalability, and seamless integration.
Validate architecture decisions before speech performance becomes a bottleneck.
Review Your TTS Architecture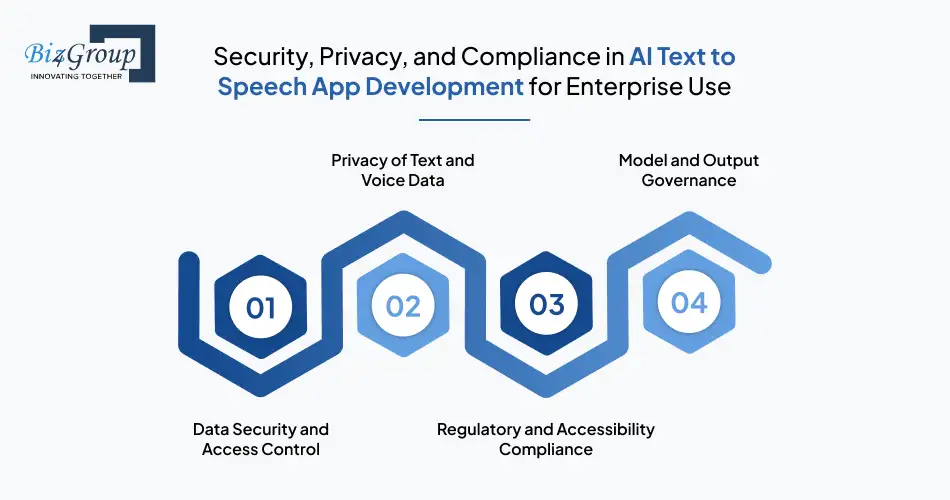
AI text-to-speech apps process sensitive inputs, written content, generated voice data, and user interaction logs. These considerations are especially critical when building AI text to speech applications for enterprise use, healthcare, or customer-facing platforms, particularly for organizations looking to create AI driven text to speech app for healthcare.
AI text-to-speech systems must protect both text inputs and generated audio outputs.
Text provided for speech synthesis may include confidential or personal information.
Depending on the industry, AI TTS apps may need to align with:
Speech output must remain predictable and safe.
Security and compliance requirements often vary by industry and scale. This is why many organizations rely on an experienced AI app development company to design AI text-to-speech systems that meet enterprise security, privacy, and regulatory expectations from day one.
Understanding the cost to develop an AI text to speech app early helps businesses plan scope, timelines, and technical depth realistically. Unlike standard apps, AI TTS development costs are influenced by voice quality, speech models, scalability, and real-time performance requirements. The cost typically ranges from $20,000 to $200,000+ based on product scope and complexity.
Below is a clear, decision-ready cost breakdown, aligned specifically with AI text to speech app development.
|
App Type |
Estimated Cost Range (USD) |
What It Typically Includes |
|---|---|---|
|
MVP AI Text to Speech App |
$20,000 – $60,000 |
Basic AI text-to-speech functionality, pre-trained neural TTS models, limited language support, simple UI, and core API integration to validate the concept |
|
Mid-Level AI TTS App |
$60,000 – $130,000 |
Enhanced voice quality, multi-language support, pronunciation controls, real-time and batch speech generation, improved UI/UX, and cloud deployment |
|
Enterprise-Grade AI TTS App |
$130,000 – $200,000+ |
Custom or fine-tuned neural TTS models, advanced voice modulation, enterprise-level scalability, security and compliance layers, analytics, and long-term optimization |
The cost of AI text to speech app development varies by depth and scale. Organizations often work with an experienced AI product development company to balance performance, scalability, and budget while planning AI text to speech solutions that can evolve with business needs.
Align voice quality, infrastructure, and budget before development begins.
Estimate TTS Cost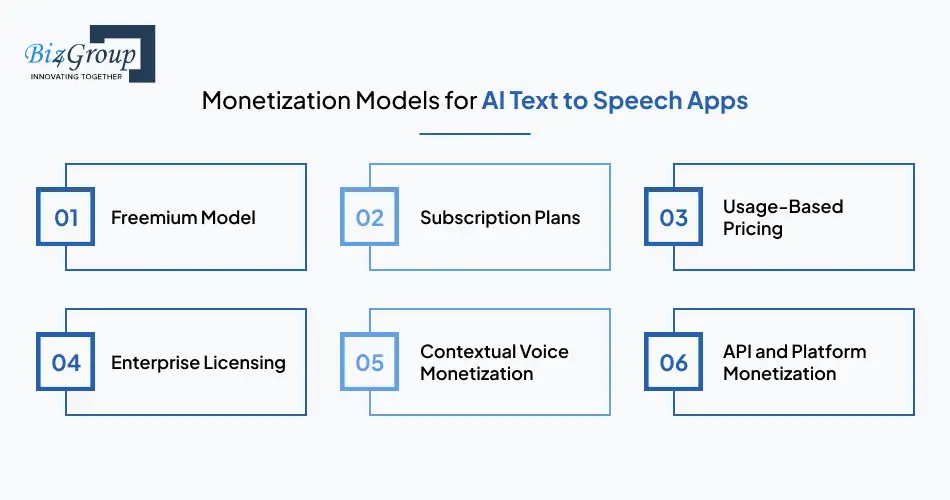
Building an AI text-to-speech app is only part of the journey. Defining the right monetization strategy determines how effectively voice capabilities translate into long-term business value. Below are six monetization models most relevant to AI text to speech app development.
A freemium approach allows users to access basic AI text-to-speech functionality while charging advanced features such as higher-quality voices, extended speech limits, or multilingual output. This model helps drive adoption before converting active users into paying customers.
Subscription-based pricing is well suited for products with recurring voice usage. Monthly or annual plans can be structured around speech volume, supported languages, or voice quality tiers, making this model effective for SaaS platforms and businesses building AI powered text to speech apps.
Pay-per-use pricing charges customers based on actual speech consumption, such as characters converted or audio minutes generated. This model aligns well with AI text-to-speech apps that support fluctuating workloads and enterprise use cases requiring flexible scaling.
Enterprise-grade AI text-to-speech deployments often rely on fixed licensing agreements. These contracts typically include higher usage thresholds, customization, and dedicated support, especially when voice capabilities are embedded into large-scale digital products or industry-specific applications.
In sector-specific applications, AI text-to-speech can generate revenue through contextual and situational voice experiences. For example, travel planning apps that use AI-driven conversational guidance can monetize premium voice narration, guided walkthroughs, or real-time travel assistance during the user journey and can monetize premium voice features within guided experiences.
AI text-to-speech capabilities can also be offered as APIs for third-party integration. This opens B2B revenue streams, particularly when businesses partner with or benchmark against top AI development companies in the USA to position their voice solutions competitively.
By combining two or more of these monetization models, an AI text-to-speech app can address diverse usage patterns, scale efficiently across user segments, and build a sustainable revenue stream while continuing to enhance voice quality and performance.
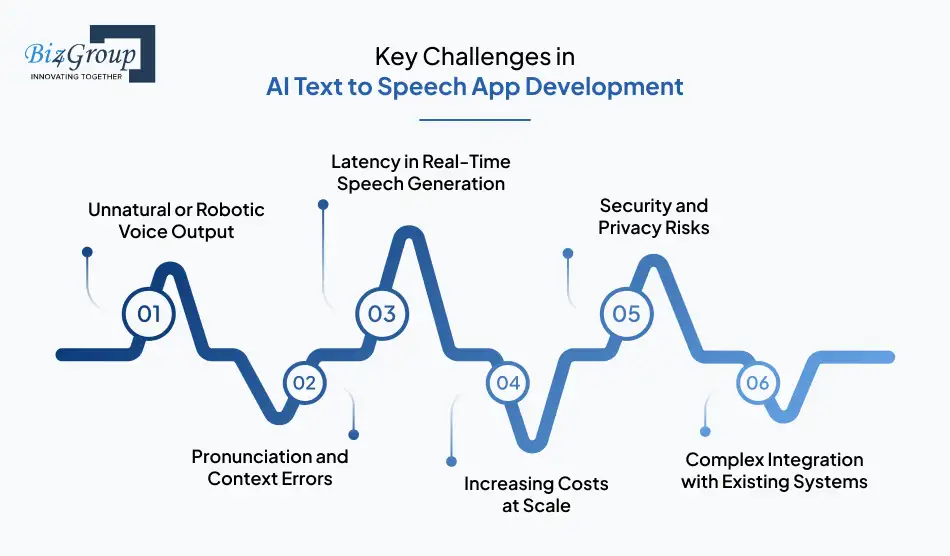
AI text-to-speech app development presents challenges that are highly specific to voice generation, performance, and scalability. Below are the most critical challenges teams face and how they are typically addressed in production-ready AI TTS applications.
|
Challenge |
How to Address It |
|---|---|
|
Unnatural or Robotic Voice Output |
Use high-quality neural text-to-speech models, apply proper text normalization, and fine-tune voice parameters to maintain natural and consistent speech delivery. |
|
Pronunciation and Context Errors |
Implement grapheme-to-phoneme conversion, context-aware rules, and custom pronunciation dictionaries for names and industry-specific terms. |
|
Latency in Real-Time Speech Generation |
Optimize inference pipelines, separate real-time and batch workflows, and deploy low-latency infrastructure to ensure fast voice responses. |
|
Increasing Costs at Scale |
Cache frequently generated speech, enable batch of audio processing, and optimize model usage to control infrastructure and inference costs. |
|
Security and Privacy Risks |
Encrypt text and audio data, enforce role-based access control, and define clear data retention policies to protect sensitive information. |
|
Complex Integration with Existing Systems |
Design API-first, modular TTS services that integrate smoothly with existing applications and enterprise platforms. |
By proactively addressing these challenges, businesses can build AI text-to-speech apps, ensuring speech generation enhances the product experience rather than becoming a bottleneck.
Building a reliable voice product requires disciplined execution. The following best practices reflect what teams consistently apply when they build AI-powered text to speech apps that scale, perform, and deliver real business value.
AI text-to-speech should be treated as a primary interaction layer, not a supporting feature. Voice playback, pacing, and control must be designed intentionally, so speech output feels natural, accessible, and aligned with how users consume spoken content.
High-quality voice output directly impacts adoption. Teams should focus early on model selection, pronunciation accuracy, and prosody control before adding secondary features. This approach helps avoid rework when refining neural speech quality later.
Real-time voice delivery and batch text-to-audio processing have different performance requirements. Separating these workflows improves latency, cost control, and system reliability when teams develop AI text to speech applications for varied use cases.
AI text-to-speech usage can grow rapidly once adopted. API-first design, modular services, and scalable inference pipelines ensure the app can handle increasing speech volumes without performance degradation.
Speech models require ongoing monitoring, tuning, and version control. Strong AI model training languages, and usage patterns evolve.
Following these best practices helps teams create AI text-to-speech apps that sound natural, scale reliably, and remain adaptable as voice usage and business requirements grow.
Building an AI text-to-speech app that delivers natural voice output, scales reliably, and integrates seamlessly into business products requires a partner with deep AI and app development expertise. That’s where Biz4Group LLC stands out.
As a trusted AI development company in USA we specialize in building scalable, production-ready AI text-to-speech applications tailored to real business use cases. Our experience spans voice-driven platforms, enterprise AI solutions, and customer-facing systems.
Here’s why businesses choose Biz4Group to develop AI text to speech applications:
Biz4Group LLC brings the technical depth, execution discipline, and product focus required to build reliable AI text-to-speech apps that perform at scale. Thus, making it an ideal partner for AI text to speech app development.
AI text to speech app development is no longer about adding voice as a feature; it’s about designing how users hear, understand, and trust your product. The right decisions across use cases, voice quality, system architecture, and scalability determine whether your solution feels like a novelty or a core business capability.
This guide outlined what it takes to build AI powered text to speech apps that deliver natural speech, scale reliably, and align with real business goals. Whether for eLearning, media, customer support, or healthcare, successful voice solutions depend on strong planning, robust speech architecture, and clear cost considerations. For many teams, this journey starts by understanding how to build an AI app that integrates voice seamlessly into existing products.
At Biz4Group, we help businesses turn AI text-to-speech ideas into scalable, market-ready applications.
Ready to move forward?
Book an appointment With our AI experts today and take the first step toward launching your AI text-to-speech app.
Developing an AI text-to-speech app starts with defining voice use cases, selecting neural TTS models, and designing voice-first user flows. The process then moves to AI integration, MVP validation, and scaling with performance, security, and cost optimization in mind.
Traditional voice solutions rely on rule-based synthesis and sounds robotic. AI text-to-speech uses neural models to generate natural, expressive speech, offering better pronunciation, tone control, scalability, and adaptability across languages and business use cases.
The cost to develop an AI text-to-speech app typically ranges from $20,000 for an MVP to $200,000+ for enterprise-grade solutions. Pricing depends on voice quality, real-time performance, language support, and customization requirements.
Yes. Many organizations build AI speech synthesis apps for eLearning and media to automate narration, improve accessibility, and scale content delivery. AI-powered voice solutions enable consistent, multilingual audio generation without manual voice recording.
When designed correctly, AI text-to-speech applications for enterprise use follow strict security practices, including data encryption, access control, and compliance-ready architecture to protect sensitive text and generated voice data.
Modern AI text-to-speech systems support custom voice creation, allowing businesses to generate branded or domain-specific voices. This capability is commonly used in customer engagement platforms, training systems, and voice-enabled enterprise applications.
The best company to develop an AI text-to-speech app combines AI expertise, speech technology experience, and full-cycle app development capabilities. Evaluating past AI projects, scalability experience, and industry knowledge is key to long-term success.

with Biz4Group today!
Our website require some cookies to function properly. Read our privacy policy to know more.