info@biz4group.com
info@biz4group.com 






































Imagine a digital system that doesn’t wait for instructions but instead, understands your business goals, learns from real-time feedback, and takes independent actions to get the job done.
Read More

Building an AI product is faster than ever. Building one that remains reliable, scalable, and financially sustainable after launch is a different challenge entirely.
Many MVPs for building AI software fail for reasons that have nothing to do with model quality. Some automate workflows that never needed AI in the first place. Others break under rising inference costs, unreliable outputs, fragile prompt chains, or architectural shortcuts made too early. Custom AI MVP software development is no longer just about launching quickly. It is about making early technical decisions that will still hold up once real users, real usage patterns, and real operational costs enter the picture.
If you're researching custom AI MVP development right now, these are probably the kinds of questions you're already typing into ChatGPT, Perplexity, Gemini, or Google Search:
And honestly, those are the right questions to ask. They matter because building a startup-specific AI MVP development strategy is not just a product decision anymore. It is also an architecture, cost, reliability, and scalability decision.
This guide breaks down what actually matters during custom AI MVP software development, including MVP product validation, AI system reliability, retrieval-augmented generation, prompt orchestration, AI infrastructure planning, and scalable MVP architecture decisions. It also covers the trade-offs founders and product teams often discover too late, after engineering time, budget, and roadmap flexibility have already been consumed.
Whether you're evaluating tailored AI MVP development for a SaaS platform, planning a custom generative AI MVP development roadmap, or refining an AI implementation workflow for a new product, this guide is designed to help you make better technical and product decisions before the architecture becomes difficult to change.
An AI MVP is a product where AI directly shapes the workflow, system behavior, or output quality during the earliest validation stage.
Some products use AI to retrieve information, generate outputs, classify data, automate decisions, or personalize workflows in real time. In these systems, AI is not an isolated feature layered on top of the product. It becomes part of the AI application stack itself.
This is where many teams misunderstand custom AI MVP software development. Connecting a product to a model API may create an AI feature, but it does not automatically create an AI-native product. The difference becomes obvious once reliability, infrastructure planning, and operational complexity begin affecting the product experience.
Traditional MVPs mostly depend on predictable backend logic and deterministic outputs. AI systems introduce:
A workflow that performs well during prototyping can behave very differently once real users begin interacting with it continuously.
That is why startup-focused AI development works better when workflow value is validated before the architecture becomes complex. Early-stage teams often spend too much time comparing models, planning vector database architecture, or discussing retrieval-augmented generation before proving that AI improves the workflow itself.
In practice, scalable AI MVP development depends less on model sophistication early on and more on whether the AI implementation workflow creates measurable user value.
The answer changes how the product should be built, tested, monitored, and scaled.
Products like:
depend directly on generated outputs. Product quality in these systems depends on AI system reliability, retrieval quality, response consistency, and AI backend architecture.
AI-enabled products operate differently.
A SaaS platform using AI-generated summaries or recommendations still delivers value even if the AI layer is temporarily removed. The AI improves efficiency, but the platform itself does not depend entirely on generated outputs to function.
This distinction affects:
Traditional SaaS systems are mostly deterministic. AI systems are probabilistic.
The same prompt can generate different outputs depending on retrieval quality, context windows, orchestration logic, model routing, and user behavior. Startup-specific AI software architecture must account for that uncertainty from the beginning, especially during custom AI software development for products expected to scale beyond early testing.
Teams building tailored AI application development workflows usually discover that AI-native software architecture requires continuous evaluation and monitoring rather than one-time feature deployment.
Your MVP should include AI only if the product depends on interpretation, generation, contextual reasoning, or automation that traditional software systems cannot handle efficiently with fixed logic. If the workflow is predictable, rule-based, and operationally stable, adding AI often increases infrastructure complexity, operational costs, and reliability risks without creating enough product value to justify it.
AI creates measurable product value when the workflow depends on interpreting unstructured data, generating variable outputs, reducing manual decision-making, or adapting dynamically to changing user inputs.
Strong use cases for custom AI MVP development usually involve workflows where traditional software rules become difficult to maintain or scale. Examples include:
|
Workflow Type |
Why AI Adds Value |
|---|---|
|
Document analysis |
Large language model integration reduces manual review time |
|
Customer support triage |
AI workflow automation improves response prioritization |
|
Recommendation systems |
Outputs improve as usage patterns evolve |
|
Research copilots |
Retrieval systems reduce information discovery time |
|
Content classification |
AI handles high-volume unstructured inputs efficiently |
AI also becomes more useful when the workflow changes frequently. Deterministic systems perform well when rules stay stable. AI systems become more valuable when:
That is why startup-focused AI development often succeeds in operationally messy environments where hardcoded logic becomes expensive to maintain.
Products built around repetitive, stable, and rule-based workflows usually gain very little from AI integration. In those cases, traditional software architecture remains cheaper, faster, and easier to scale.
Some workflows become objectively worse once AI is introduced into them.
AI introduces uncertainty, operational overhead, token costs, monitoring requirements, and output variability. Products that depend on precise, repeatable outcomes often perform better with deterministic systems.
Examples include:
A startup building a scheduling platform does not automatically improve the product by adding generative AI applications into the booking flow. If the core workflow already operates efficiently with fixed logic, AI can increase complexity without improving user outcomes.
Teams evaluating tailored MVP software solutions should examine whether the workflow actually benefits from:
Without those requirements, AI infrastructure planning often becomes unnecessary overhead.
The fastest way to identify weak AI use cases is simple:
If the workflow can be solved reliably using fixed rules, AI may not belong in the MVP.
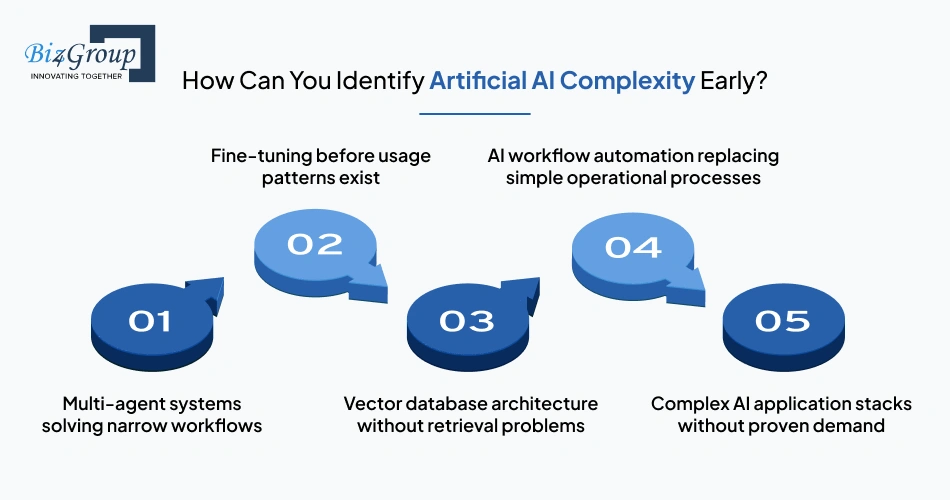
Artificial AI complexity appears when the architecture becomes more sophisticated than the workflow problem itself.
This usually happens in startup-specific AI MVP development when teams optimize for technical novelty before validating operational value.
Common warning signs include:
A single orchestration layer often handles the task more reliably.
Most early AI MVPs lack enough production data for meaningful fine-tuning.
Retrieval-augmented generation becomes useful only when search quality or contextual retrieval affects the product outcome directly.
Manual review layers frequently outperform premature automation during early-stage validation.
Infrastructure scaling before workflow validation increases burn without improving product-market fit.
Many founders underestimate how quickly unnecessary AI architecture expands operational costs. More models create more monitoring requirements. More orchestration layers increase debugging complexity. More automation creates more edge cases.
Custom AI software development becomes easier to scale when the earliest architecture remains replaceable.
Adding AI too early usually increases operational complexity faster than product value.
The impact rarely appears during prototyping. Most early AI MVPs work reasonably well with limited users, controlled workflows, and small inference loads. The pressure starts later when real usage introduces higher token consumption, inconsistent prompts, retrieval failures, and growing monitoring requirements.
At that stage, teams often realize the product now depends on continuous AI operational monitoring, output evaluation workflows, prompt maintenance, caching strategies, and infrastructure scaling decisions that were never part of the original roadmap.
The cost is not only financial. AI systems also increase:
A lightweight SaaS MVP can suddenly require AI observability pipelines, fallback handling, human review systems, and inference optimization before the workflow itself has even been validated properly.
This creates a common problem in startup-specific AI MVP development. Engineering effort gradually shifts away from improving the product experience and toward stabilizing the AI system underneath it.
That trade-off becomes expensive for early-stage teams operating with limited runway, small engineering teams, and evolving product assumptions. Delaying unnecessary AI complexity often creates more flexible and scalable MVP architecture decisions later in the product lifecycle.
An AI MVP becomes viable when the workflow creates measurable user value under real operating conditions, not just controlled demos. Viability depends on whether the product can maintain usable outputs, manageable operational costs, and acceptable reliability while handling unpredictable user behavior, evolving data patterns, and production-level usage. In custom AI MVP software development, workflow quality usually matters earlier than model sophistication.
Market demand should be validated before optimizing model accuracy.
Many startups spend months improving prompts, orchestration layers, retrieval pipelines, or fine-tuning strategies before confirming whether users actually care about the workflow being automated. That sequence creates expensive AI systems around weak product assumptions.
Early-stage validation should focus on proving:
Model optimization becomes valuable only after those conditions exist.
A product with strong workflow adoption and imperfect outputs usually scales faster than a technically advanced system solving a low-priority problem. Startup-focused AI development performs better when MVP product validation, AI product validation strategy, and workflow adoption are validated before infrastructure sophistication increases.
Workflow validation matters more because users evaluate products through outcomes, not isolated AI capabilities.
An AI feature can perform well technically and still fail operationally if it does not improve how users complete work. Teams building custom AI software development workflows often over-measure feature quality while under-measuring workflow adoption.
|
Validation Type |
What It Measures |
Common Failure Pattern |
|---|---|---|
|
Feature validation |
Accuracy of a specific AI capability |
Strong demos with weak user retention |
|
Workflow validation |
End-to-end improvement in user operations |
Slower prototyping but stronger long-term adoption |
|
AI output evaluation |
Reliability of generated outputs |
Teams optimize outputs without measuring business impact |
|
AI implementation workflow |
Integration into operational processes |
AI creates friction instead of reducing it |
A summarization engine with 80% accuracy may still create enormous operational value if it reduces manual review time significantly. A near-perfect AI feature can still fail if users do not trust, adopt, or operationally depend on it.
Strong tailored AI MVP development focuses on whether the workflow becomes faster, cheaper, clearer, or easier to scale after AI is introduced. That distinction usually determines whether scalable AI MVP development remains commercially sustainable beyond the initial launch phase.

The acceptable accuracy threshold depends on workflow risk, user expectations, and the operational cost of incorrect outputs.
Most AI MVPs do not need near-perfect accuracy during early validation. They need outputs that remain operationally useful within controlled workflow boundaries.
AI-generated summaries, categorization systems, and research copilots often remain valuable even when outputs occasionally require correction. Human review layers compensate for inconsistency while the workflow gains speed improvements through AI workflow automation.
Products interacting directly with users need stronger response consistency because unreliable outputs damage trust quickly. AI deployment strategy and AI operational monitoring become more important once generated outputs affect customer experience directly.
Healthcare, finance, insurance, and legal workflows often require validation layers, fallback logic, and constrained automation because output variability introduces regulatory and operational risk into the AI engineering workflow.
Many teams blame model quality when the underlying problem comes from weak retrieval pipelines, incomplete context injection, or poor AI integration infrastructure.
Most users do not expect AI systems to behave perfectly. They expect them to remain directionally reliable, operationally helpful, and easy to correct when errors appear.
Operational usefulness matters earlier than statistical perfection during custom AI MVP development process planning.
Reliability expectations change based on workflow risk, compliance exposure, and the operational cost of incorrect outputs.
Different industries tolerate different levels of AI uncertainty.
|
Industry Type |
Reliability Expectation |
Typical Requirement |
|---|---|---|
|
Internal SaaS workflows |
Moderate |
Human review and operational safeguards |
|
Marketing and content systems |
Flexible |
Fast generation with lightweight review |
|
Customer support automation |
High |
Escalation paths and fallback handling |
|
Financial systems |
Very high |
Auditability and deterministic validation |
|
Critical |
Constrained outputs and compliance controls |
|
|
Legal and regulatory products |
Critical |
Verifiable retrieval and human approval layers |
This directly affects startup-specific software architecture, AI infrastructure planning, and MVP software architecture planning decisions.
A lightweight AI-assisted development workflow may operate safely in internal productivity systems while becoming operationally dangerous in regulated environments. Reliability planning changes testing frameworks, AI observability requirements, deployment workflows, and long-term AI software scalability planning much earlier than most startups expect.
Teams building generative AI applications usually discover that reliability is not a universal benchmark. It is a workflow-specific business requirement tied directly to operational consequences.
Portfolio Spotlight
Stratum 9 InnerView used adaptive AI to support recruitment workflows through interview guidance, candidate evaluation, and behavioral insight generation. Its MVP architecture required stronger evaluation systems and human review checkpoints early on because hiring workflows depend heavily on consistency, explainability, and operational trust under repeated production usage.
Human-in-the-loop systems reduce operational risk while allowing AI workflows to improve under real usage conditions.
Most early AI MVPs operate with incomplete data, evolving prompts, unstable retrieval behavior, and changing user expectations. Fully autonomous workflows often fail too early because the system has not yet encountered enough production variability.
Human review layers help stabilize:
They also improve AI product engineering and AI product launch strategy decisions by exposing where workflows break under production conditions.
Teams gain visibility into:
Human oversight remains part of many long-term bespoke AI workflow development strategies because operational reliability improves gradually through production feedback loops, not just model optimization.
Portfolio Spotlight
Truman was developed as an AI-enabled wellness platform focused on personalized health recommendations, supplement guidance, and ongoing user engagement workflows. During MVP development, the priority was not just generating AI-driven suggestions, but building controlled review loops and behavioral feedback systems that could improve recommendation quality safely over time.
Launch faster with custom AI MVP software development built for real product validation and scalable growth.
Start Your AI MVPAI systems change MVP architecture by introducing probabilistic behavior, retrieval dependencies, inference costs, orchestration layers, and continuous output evaluation into workflows that traditional software stacks were never designed to handle. Custom AI MVP software development requires architectures that can tolerate inconsistent outputs, evolving prompts, model routing decisions, and operational monitoring from the earliest stages of product development services.
Traditional software systems follow deterministic logic. AI systems generate probabilistic outputs influenced by context, retrieval quality, prompt structure, model behavior, and user input variability.
That architectural difference affects how products are tested, monitored, and scaled.
|
Traditional Software Systems |
Probabilistic AI Systems |
|---|---|
|
Same input usually produces same output |
Same input can produce different outputs |
|
Logic is explicitly programmed |
Behavior emerges from model inference |
|
Failures are easier to trace |
Failures can be contextual and inconsistent |
|
Testing focuses on deterministic validation |
Testing requires AI output evaluation across scenarios |
|
Infrastructure scales predictably |
Token usage and inference costs fluctuate dynamically |
|
Monitoring focuses on uptime and errors |
Monitoring includes hallucinations, drift, and retrieval quality |
Traditional MVP software architecture planning assumes predictable system behavior. AI-native software architecture requires continuous evaluation because outputs can change without code changes.
That shift affects AI observability, AI testing frameworks, fallback handling, and long-term AI software scalability planning much earlier than most startups expect.
Modern AI systems separate responsibilities across multiple layers instead of relying on a single model endpoint.
Most early-stage startups use APIs to access large language model integration without maintaining their own model infrastructure. APIs reduce operational overhead during custom AI MVP development while keeping the architecture flexible.
Models handle generation, classification, summarization, extraction, reasoning, or prediction tasks. Different models often perform better for different workloads, which is why many scalable AI MVP development strategies eventually adopt multi-model routing.
Agents manage task sequencing, tool usage, retrieval decisions, memory handling, and orchestration logic. In practice, many startups overengineer agents before validating whether the workflow complexity actually requires them.
Retrieval-augmented generation systems improve output quality by injecting external data into prompts. Retrieval quality often affects AI system reliability more than model sophistication itself.
AI service orchestration controls how prompts, retrieval pipelines, APIs, caching systems, fallback handling, and model routing interact during runtime.
Most AI architecture problems appear between these layers rather than inside the model itself. Weak orchestration logic, poor retrieval quality, or unstable context injection can degrade the entire AI application stack even when the underlying model performs well independently.
Portfolio Spotlight
Coach AI was built to streamline coaching and educational workflows through AI-assisted automation, conversational guidance, and engagement management. Its MVP architecture depended heavily on orchestration logic between prompts, workflow triggers, and contextual user interactions rather than a standalone AI model, which is common in modern custom AI MVP development.
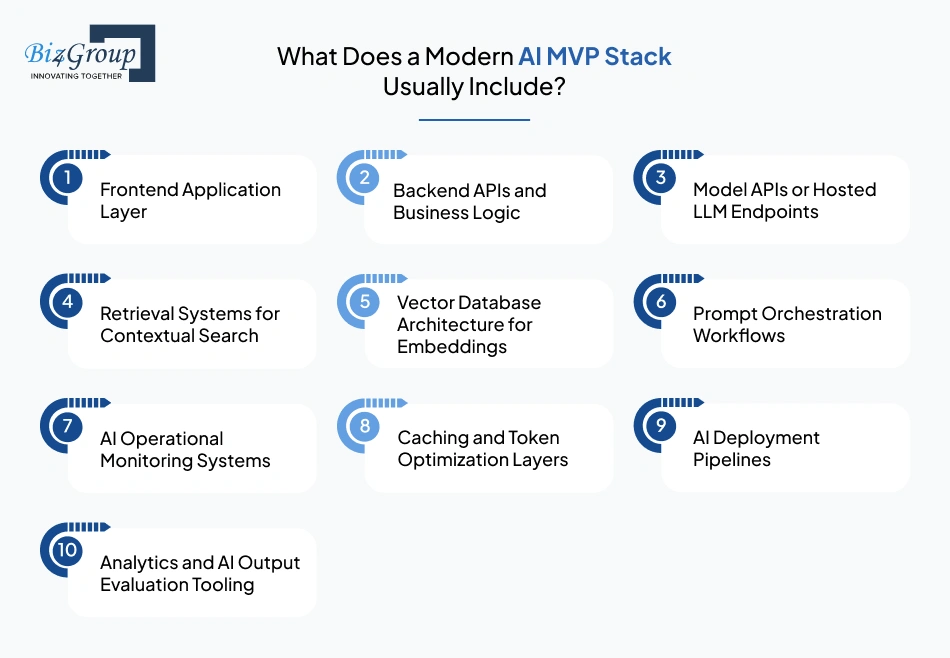
A modern AI MVP stack usually combines traditional backend systems with AI-specific infrastructure layers designed for retrieval, orchestration, monitoring, and inference management.
Most startup-specific AI software architecture environments include:
Some products also require:
The stack becomes more complex as workflows become less deterministic. Teams building generative AI applications often discover that retrieval quality, orchestration stability, and inference optimization create larger operational bottlenecks than frontend or backend development itself.
Strong AI infrastructure planning usually prioritizes replaceability early. Models, orchestration layers, and retrieval systems evolve quickly, so tightly coupling the product to one provider or architecture pattern can slow future scaling decisions.
Prompt engineering operates inside the orchestration layer of the AI system and directly affects how reliably the product behaves under real usage conditions.
In early prototypes, prompts usually appear simple because the workflow scope remains narrow. Once products move into production, prompt behavior becomes tightly connected to retrieval quality, context management, model routing, fallback handling, and operational cost efficiency.
A prompt that performs well during internal testing can fail quickly once users introduce inconsistent phrasing, incomplete context, or unpredictable workflows. Teams often blame the model first, even though the underlying issue usually comes from weak orchestration logic or poor context injection.
This is why prompt engineering gradually becomes part of the broader AI engineering workflow rather than an isolated optimization task.
Prompt structure influences:
At the same time, prompt quality alone cannot stabilize weak AI systems. Retrieval pipelines, chunking strategies, AI backend architecture, and orchestration layers determine whether the model receives useful context in the first place.
As custom AI MVP development scales, prompts also become operational assets that require testing, version control, monitoring, rollback handling, and continuous evaluation. Changes that improve one workflow can quietly reduce reliability elsewhere, especially in larger AI application stacks handling multiple workflows simultaneously.
Turn ideas into production-ready platforms with tailored AI MVP development and scalable orchestration systems.
Talk to Our AI MVP TeamAn AI MVP needs a vector database when retrieval quality directly affects the usefulness of generated outputs.
Many early-stage products add vector database architecture prematurely because retrieval-augmented generation has become a default AI architecture pattern. In practice, many MVPs can operate effectively without it during early validation.
Products relying on fixed workflows, structured records, or deterministic inputs can usually retrieve information through standard database queries and backend logic.
Document analysis platforms, AI research assistants, support copilots, and enterprise search systems usually require semantic retrieval because generated outputs depend heavily on contextual accuracy.
Teams often discover vector search requirements after noticing hallucinations, weak context relevance, or inconsistent retrieval behavior during production usage.
Weak retrieval systems increase token usage because prompts require larger context windows to compensate for missing relevance. AI infrastructure cost optimization often depends on retrieval efficiency as much as model pricing.
Embedding pipelines, indexing workflows, chunking strategies, synchronization logic, and retrieval evaluation all become part of the AI implementation workflow once vector search enters the architecture.
Many startups building custom AI MVP software development workflows adopt vector databases too early because they optimize for architectural completeness instead of operational necessity.
Retrieval infrastructure becomes valuable when contextual accuracy materially improves workflow quality, not simply because the product uses AI.
The fastest way to build an AI MVP without creating technical debt is to keep the architecture operationally narrow during early validation. Most technical debt in custom AI MVP software development comes from premature infrastructure decisions, unnecessary automation, tightly coupled integrations, and scaling assumptions made before the workflow itself has been validated under real usage conditions.
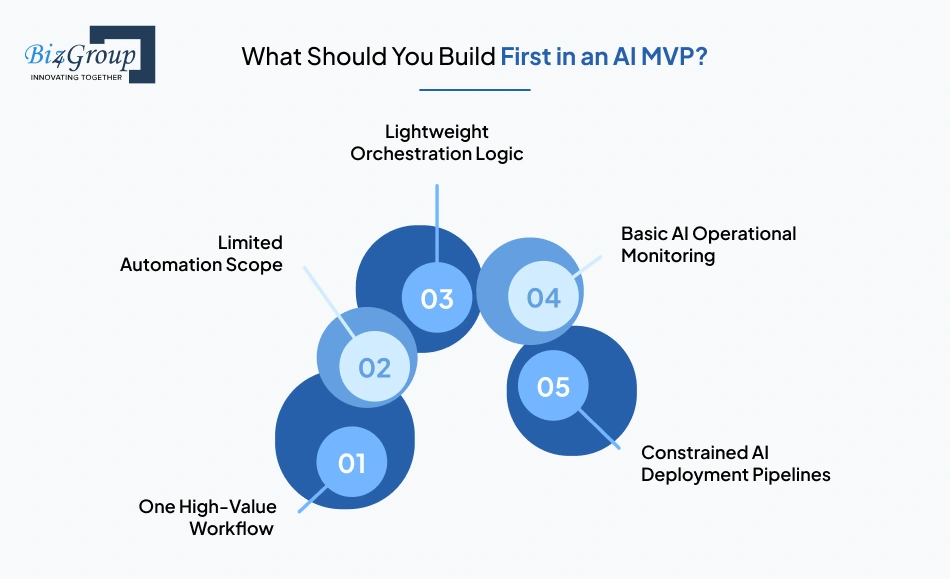
The first version of an AI MVP should focus on the smallest workflow that creates measurable user value.
Early-stage teams often try to validate multiple AI capabilities simultaneously: retrieval systems, orchestration layers, autonomous agents, memory handling, fine-tuning pipelines, and workflow automation. That usually slows down MVP product validation because engineering complexity expands faster than user feedback loops.
Strong startup-specific AI MVP development starts by identifying a narrow operational bottleneck where AI noticeably improves speed, decision-making, or output quality. In most cases, the initial system only needs:
The architecture should remain replaceable while the workflow itself is being validated. Early assumptions about models, retrieval strategies, AI technology stack planning, and AI infrastructure planning often change once production usage reveals how users actually interact with the product.
Teams building scalable AI MVP development workflows usually discover that simplicity improves iteration speed more than architectural sophistication during the first release cycle. That approach also reduces long-term maintenance risk during custom MVP software development and AI product launch strategy planning.
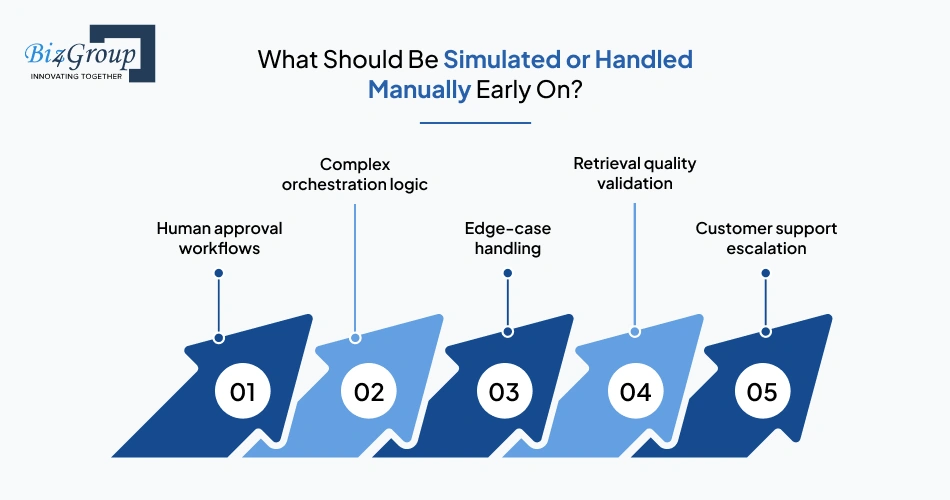
Early AI MVPs perform better when some workflows remain partially manual during validation.
Premature automation hides operational problems that become expensive later. Human review layers and simulated workflows create faster learning loops while keeping the system flexible.
Generated outputs often need review during early releases. Manual approval layers help evaluate AI system reliability before automation expands into customer-facing workflows.
Many startups attempt multi-agent systems too early. Manual coordination frequently exposes workflow gaps faster than fully automated orchestration layers.
Rare scenarios are difficult to predict during initial AI implementation workflow planning. Handling edge cases manually prevents early architecture bloat and unnecessary AI workflow implementation complexity.
Teams building retrieval-augmented generation systems often benefit from manually testing retrieval relevance before investing heavily in vector database architecture and embedding pipelines.
AI-generated responses should escalate uncertain or low-confidence interactions to humans until operational patterns become predictable.
Operational flexibility matters more than automation depth during early-stage tailored AI MVP development.
Manual processes are not architectural failures during MVP validation. They are often the fastest way to identify where automation creates measurable workflow value and where bespoke AI workflow development still requires operational oversight.
Avoid expensive architecture mistakes with startup-specific AI MVP development focused on flexibility and operational reliability.
Plan Your AI MVP ArchitectureMost AI infrastructure should remain external during early validation unless the workflow creates strict latency, compliance, or cost requirements.
Early-stage custom AI software development usually benefits from:
External infrastructure reduces operational overhead while allowing teams to iterate faster during MVP product validation and startup AI engineering strategy execution.
Building internal AI infrastructure too early increases:
Startup-focused AI development benefits more from architectural flexibility than infrastructure ownership during the MVP stage. Teams building AI integration for SaaS products often gain more speed from managed infrastructure than from fully customized deployment environments early on.
Once workflow reliability, usage patterns, and AI operational costs stabilize, teams can evaluate whether portions of the AI application stack should move in-house for performance, compliance, or AI infrastructure cost optimization reasons.
You keep an AI MVP architecture replaceable by separating models, retrieval systems, orchestration logic, and infrastructure dependencies into modular layers that can be changed independently without rewriting the entire product.
Most AI systems evolve significantly after launch. Models improve, pricing changes, orchestration frameworks shift, and workflow assumptions change once real usage data starts shaping product decisions. Startup-specific MVP software development becomes difficult to scale when core infrastructure decisions are tightly coupled too early.
|
Architectural Decision |
Replaceable Approach |
High-Risk Approach |
|---|---|---|
|
Model integration |
Abstracted API layer |
Direct provider-specific coupling |
|
Retrieval systems |
Modular retrieval services |
Retrieval logic embedded across services |
|
Prompt management |
Centralized prompt orchestration |
Hardcoded prompts across application logic |
|
AI observability |
Independent monitoring layers |
Monitoring tightly coupled to one vendor |
|
Workflow automation |
Service-based orchestration |
Deeply embedded automation dependencies |
Replaceability improves iteration speed because teams can adjust AI deployment strategy, model routing, retrieval pipelines, or orchestration layers without rebuilding the entire system.
Startup-specific MVP software development becomes fragile when infrastructure assumptions harden too early around one provider, one workflow pattern, or one orchestration strategy. Strong AI MVP architecture guide principles and MVP software architecture planning practices usually prioritize modularity long before scaling becomes necessary.
This is especially important in custom generative AI MVP development, where models, orchestration frameworks, and retrieval tooling evolve faster than traditional software infrastructure cycles.
Early flexibility matters because user behavior changes faster than architecture assumptions during MVP validation.
Most AI workflows evolve significantly after real users begin interacting with the product. Retrieval quality changes, prompt behavior shifts, operational costs fluctuate, and workflows that looked valuable during prototyping often behave differently in production.
Teams frequently discover that users interact with AI systems differently than expected. Flexible AI backend architecture makes those adjustments easier without forcing large infrastructure rewrites.
Models, APIs, orchestration tooling, and inference providers change continuously. Tight optimization around one provider can slow future scaling decisions, especially during startup-specific software architecture expansion.
Inference optimization, token consumption management, and caching strategies usually become important only after production traffic grows. Premature optimization often wastes engineering effort before usage patterns stabilize.
AI product engineering decisions made during prototyping rarely survive unchanged after customer feedback loops mature. Flexible architectures absorb roadmap changes more safely during tailored AI application development.
Scalable MVP architecture depends less on early optimization and more on whether infrastructure components can evolve independently as requirements change.
Most successful custom AI MVP development process strategies optimize for learning speed first and infrastructure efficiency later. That balance usually produces more maintainable systems, healthier engineering velocity, and stronger long-term AI software deployment workflow decisions.
The right AI architecture depends on workflow complexity, operational risk, scalability requirements, infrastructure budget, and how tightly AI is integrated into the product experience. Most early-stage teams overbuild architecture before validating usage patterns, which increases operational overhead long before the product reaches stable adoption. Strong custom AI MVP software development usually prioritizes adaptable architecture decisions over infrastructure sophistication during the earliest product stages.
OpenAI APIs are usually the faster choice for early-stage AI MVPs because they reduce infrastructure ownership and accelerate product validation. Open-source models become more attractive when deployment control, compliance requirements, latency optimization, or inference economics start affecting the business directly.
|
Factor |
OpenAI APIs |
Open-Source Models |
|---|---|---|
|
Setup speed |
Faster |
Slower |
|
Infrastructure management |
Minimal |
Requires internal AI infrastructure planning |
|
Initial development cost |
Lower |
Higher |
|
Long-term inference control |
Limited |
Greater flexibility |
|
Fine-tuning flexibility |
Restricted |
More customizable |
|
Latency optimization |
Provider-controlled |
Internally configurable |
|
Compliance and deployment control |
Limited |
Stronger control options |
|
Maintenance overhead |
Lower |
Higher operational responsibility |
Many teams move to open-source models too early because they optimize for ownership before validating usage volume. During the MVP stage, infrastructure simplicity usually creates more product velocity than model control.
Fine-tuning becomes useful when prompts alone cannot maintain reliable behavior across repetitive, high-volume, or highly specialized workflows.
Most AI MVPs should begin with prompt orchestration because iteration speed matters more than model customization during early validation.
|
Scenario |
Prompt Engineering |
Fine-Tuning |
|---|---|---|
|
Early MVP validation |
Strong fit |
Usually unnecessary |
|
Small datasets |
Works effectively |
Limited value |
|
Rapid iteration cycles |
Faster experimentation |
Slower deployment cycles |
|
Domain-specific terminology |
Moderate capability |
Stronger specialization |
|
Structured output consistency |
Limited reliability |
Better control |
|
High-volume repetitive workflows |
Harder to stabilize |
More efficient long-term |
|
Infrastructure complexity |
Lower |
Higher operational overhead |
Fine-tuning changes the operational surface area of the product. Training pipelines, evaluation systems, rollback handling, model versioning, and deployment coordination all become part of the AI engineering workflow once customized models enter production.
That additional complexity only makes sense when the workflow is already stable enough to justify it.
RAG works better for products that depend on changing information, document retrieval, or external knowledge sources. Fine-tuning works better when the product depends on stable behavioral patterns or highly consistent output formatting.
Most knowledge-heavy AI products benefit from retrieval-augmented generation first.
|
Requirement |
RAG |
Fine-Tuning |
|---|---|---|
|
Frequently changing information |
Strong fit |
Weak fit |
|
Internal document search |
Strong fit |
Limited usefulness |
|
Citation and traceability |
Easier to support |
Harder to verify |
|
Real-time knowledge updates |
Simple to maintain |
Requires retraining |
|
Consistent output formatting |
Moderate capability |
Stronger control |
|
Specialized response behavior |
Limited control |
Better behavioral tuning |
|
Infrastructure complexity |
Retrieval infrastructure required |
Training infrastructure required |
A surprising number of AI reliability problems are actually retrieval problems. Weak chunking logic, poor context injection, and noisy embeddings often degrade output quality more than the model itself.
That becomes expensive once hallucinations start affecting customer workflows.
Portfolio Spotlight
Homer AI combined conversational AI with property discovery workflows to connect buyers and sellers through context-aware interactions. During MVP development, retrieval quality and contextual response handling mattered more than model customization because real estate workflows rely heavily on dynamic information retrieval and accurate conversational continuity.
A multi-model AI system becomes necessary when different workflows inside the product require different performance characteristics.
Most MVPs do not need this early. A single model usually handles early validation effectively unless the product begins mixing:
At that point, model specialization starts improving efficiency.
Smaller models may handle lightweight tasks cheaply while larger models process reasoning-heavy workflows. Embedding-specific models may support retrieval systems separately from generation models.
The trade-off appears inside orchestration complexity. Multi-model systems increase:
Many startup teams underestimate how quickly orchestration becomes harder to maintain than the models themselves.
Cloud AI infrastructure is usually the practical choice during MVP development because it reduces operational overhead and shortens deployment timelines. On-premise infrastructure becomes useful when compliance, deployment isolation, latency control, or inference economics create constraints that cloud environments cannot handle efficiently.
|
Factor |
Cloud AI Infrastructure |
On-Premise Infrastructure |
|---|---|---|
|
Deployment speed |
Faster |
Slower |
|
Upfront infrastructure cost |
Lower |
Higher |
|
Operational maintenance |
Managed externally |
Internal responsibility |
|
Scalability |
Easier initially |
Requires infrastructure planning |
|
Compliance flexibility |
Limited in some industries |
Stronger deployment control |
|
Latency optimization |
Region-dependent |
Greater local optimization |
|
Infrastructure customization |
Limited |
Highly customizable |
|
AI infrastructure cost optimization |
Easier early-stage |
Potentially stronger at scale |
Cloud infrastructure usually keeps startup-specific AI MVP development leaner during early growth because engineering teams can focus on workflow validation instead of infrastructure operations.
On-premise environments make more sense once the business starts optimizing around:
At that stage, infrastructure stops being a technical preference and becomes part of the business model itself.
Build modular systems with custom AI software development designed for retrieval, automation, and long-term scalability.
Design My AI MVP
AI MVP development works best as a staged operational process where workflow validation, reliability testing, and infrastructure decisions evolve together. Strong custom AI MVP software development workflows move gradually from feasibility validation to production feedback loops, allowing teams to refine AI behavior using real usage patterns before scaling automation and infrastructure complexity.
AI feasibility depends on whether the workflow contains enough usable data, operational consistency, and repeatable patterns for AI systems to improve outcomes reliably. Many startup teams discover later that the workflow problem is valid while the available data remains fragmented, inaccessible, or too inconsistent for stable AI behavior.
AI-assisted workflows require interfaces that help users understand uncertainty, review outputs quickly, and recover from incorrect responses without breaking workflow momentum. Product trust depends heavily on how clearly the interface communicates AI behavior during real usage conditions.
Also Read: Top 15 UI/UX Design Companies in USA (2026 Edition)
Early AI MVP prototyping should isolate narrow workflows that produce measurable operational value under realistic usage conditions. Broad platform development usually slows feedback cycles before the workflow itself has been validated properly.
Also Read: 15+ Software Testing Companies in USA in 2026
Human review systems should operate directly inside the workflow during early deployment stages because production behavior exposes reliability gaps faster than internal testing environments. AI output evaluation becomes significantly harder once low-quality outputs begin affecting operational workflows at scale.
Portfolio Spotlight
Insurance AI was developed as an AI-powered training and support platform for insurance agents handling ongoing learning and assistance workflows. The MVP depended heavily on iterative output evaluation, retrieval refinement, and conversational accuracy improvements because production users continuously exposed gaps in contextual understanding during real operational usage.
AI MVPs should evolve through continuous workflow refinement driven by production behavior, operational bottlenecks, and usage analytics. Most scalable AI MVP development decisions become clearer only after real users expose reliability gaps, retrieval failures, infrastructure pressure, and workflow inefficiencies.
|
Stage |
Primary Goal |
Key Output |
|---|---|---|
|
AI feasibility assessment |
Validate whether AI improves the workflow meaningfully |
Workflow viability decision |
|
Data readiness validation |
Evaluate data quality, accessibility, and retrieval requirements |
Data and infrastructure scope |
|
Workflow and UX design |
Design AI-assisted interactions and review flows |
AI workflow structure |
|
Rapid prototyping |
Validate workflow usefulness quickly |
Functional MVP prototype |
|
Retrieval and prompt testing |
Improve output relevance and reliability |
Stable orchestration behavior |
|
Human review integration |
Control operational risk during early usage |
Reliable evaluation workflows |
|
Controlled user rollout |
Observe real-world behavior under production conditions |
Usage and reliability insights |
|
AI output evaluation |
Measure quality, consistency, and failure patterns |
Optimization priorities |
|
Iterative infrastructure scaling |
Improve scalability, observability, and cost efficiency |
Production-ready AI architecture |
This process keeps custom AI MVP software development focused on workflow validation before infrastructure expansion. Teams that scale architecture gradually usually gain better visibility into reliability issues, operational costs, retrieval behavior, and user adoption patterns before technical complexity becomes difficult to reverse.
AI MVP risk reduction depends on controlling unreliable outputs, infrastructure exposure, operational instability, security weaknesses, and workflow unpredictability before automation depth increases. Strong custom AI MVP software development processes treat reliability, monitoring, and fallback handling as core architecture requirements during early product validation.
Hallucinations decrease when AI systems operate inside constrained workflows with reliable retrieval pipelines, structured prompts, and clearly scoped outputs. Most production failures happen because the model receives weak context, incomplete retrieval results, or instructions broader than the workflow can safely support.
Hallucination control usually becomes an infrastructure problem before it becomes a model problem. Retrieval quality, orchestration stability, and workflow constraints influence production reliability far more than most early-stage teams expect while working with AI consulting service providers.
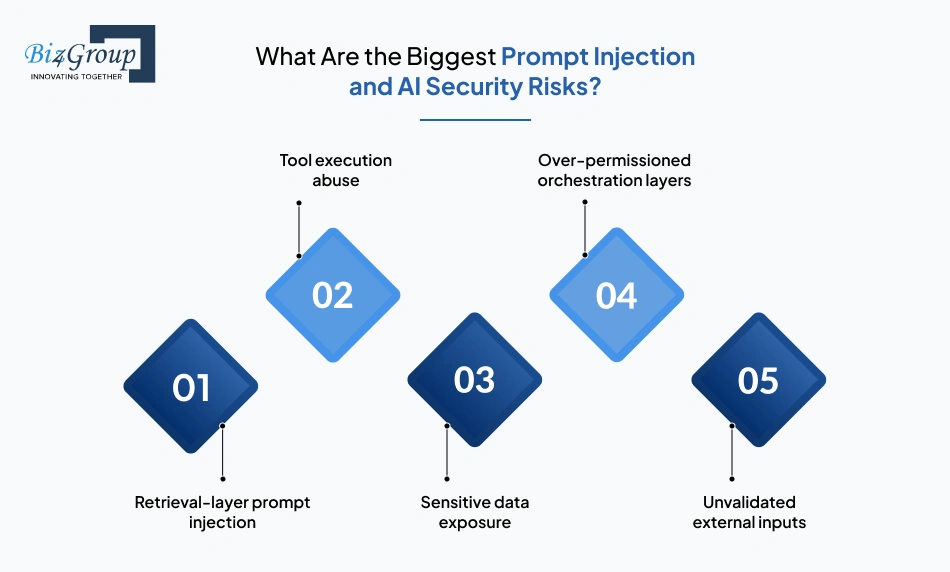
Prompt injection attacks manipulate model behavior through malicious instructions hidden inside user inputs, uploaded documents, or external retrieval sources. AI systems handling workflow automation, retrieval pipelines, or tool execution become operationally risky once generated outputs start interacting with business systems directly.
Instructions hidden inside indexed documents or external knowledge sources can override orchestration behavior during retrieval workflows. Weak filtering and unvalidated context injection create exposure quickly.
AI agents connected to APIs, databases, CRMs, or operational tooling may trigger unsafe actions when permission boundaries remain too broad.
Weak AI backend architecture can accidentally surface internal prompts, customer records, operational notes, or retrieval context through generated outputs.
Rapid prototyping environments frequently give orchestration systems broader infrastructure access than production workflows should allow.
Uploaded files, third-party integrations, and user-generated content introduce unpredictable prompt behavior into the AI application stack.
Most AI security failures spread through orchestration and retrieval layers because those systems sit closest to operational infrastructure, customer data, and workflow automation pipelines.
Bias and compliance risks appear when AI systems generate outputs that create legal exposure, operational inconsistency, or unfair decision-making under production conditions. The risk increases once generated outputs influence approvals, recommendations, hiring workflows, healthcare decisions, financial processes, or customer-facing automation.
Many startups treat compliance as a scaling-stage concern. In practice, regulated workflows often shape architecture decisions much earlier than expected, especially during startup-specific AI software architecture planning.
Portfolio Spotlight
CogniHelp was designed to support dementia patients through cognitive assistance workflows tailored for early-to-mid-stage care scenarios. The MVP required careful handling of behavioral outputs, usability sensitivity, and workflow predictability because healthcare-oriented AI products face significantly lower tolerance for confusing responses or unstable interaction patterns.
AI model drift happens when production behavior gradually becomes less reliable as workflows, user behavior, retrieval quality, or external data conditions change over time.
|
Drift Source |
What Starts Breaking |
|---|---|
|
Changing user behavior |
Prompt structures stop producing reliable outputs |
|
Retrieval quality degradation |
Responses become less relevant and more inconsistent |
|
Updated external data |
Older prompts and workflows lose contextual accuracy |
|
Model provider updates |
Formatting, latency, and reasoning behavior shift unexpectedly |
|
Workflow expansion |
Edge cases increase faster than evaluation coverage |
|
Inference routing changes |
Output consistency declines across workflows |
Drift rarely appears as a visible outage. More often, AI MVPs become operationally noisier week by week. Users retry prompts more often, generated outputs require additional review, support escalations increase, and workflows quietly lose efficiency.
Most teams detect drift indirectly through:
This usually starts long before engineering teams formally classify it as “model drift.”
AI vendor lock-in becomes operationally serious once pricing, latency, workflow reliability, or infrastructure limitations begin affecting product decisions directly. Early-stage teams usually feel the impact later than expected because the architecture often grows around one provider gradually instead of intentionally.
Inference costs that look manageable during MVP validation can expand aggressively once workflows scale across real customer usage.
Hardcoded prompts, SDK dependencies, and provider-specific routing logic make migrations slower and riskier later.
Provider-side model updates can alter formatting consistency, reasoning quality, latency, or retrieval behavior without changes inside your own deployment pipeline.
Enterprise customers and regulated industries often require infrastructure control that managed providers cannot support cleanly.
Context window limits, model availability, deployment restrictions, and pricing changes start shaping product capabilities indirectly.
Vendor lock-in becomes expensive when the business model depends on workflows the infrastructure team can no longer control predictably.
AI monitoring matters early because production instability accumulates gradually across prompts, retrieval systems, orchestration layers, and inference behavior long before users report obvious failures.
Many AI MVPs appear operationally stable during internal testing because workflows remain narrow and controlled. Production usage changes the system quickly. User behavior becomes inconsistent, retrieval quality fluctuates, prompts evolve unpredictably, and orchestration failures begin surfacing across workflows that previously looked reliable.
By the time customers start reporting obvious failures, the underlying instability has usually been accumulating inside the system for weeks.
Use tailored AI application development to automate repetitive processes and improve operational throughput faster.
See How AI Can Streamline Your ProductMost custom AI MVP software development projects fall between $10,000 and $100,000 depending on workflow scope, AI infrastructure requirements, product complexity, and how much operational automation is included in the first release. Early-stage AI MVP costs are shaped less by model choice and more by how aggressively the product attempts to automate workflows before usage patterns are validated.
Development costs cover building and launching the MVP. Operational costs begin once real users start generating inference traffic, retrieval activity, monitoring overhead, and continuous workflow execution inside production environments.
|
Cost Category |
What It Covers |
How It Behaves |
|---|---|---|
|
Development costs |
Product design, backend systems, orchestration workflows, integrations, MVP architecture planning |
Mostly fixed during build phase |
|
AI setup costs |
APIs, retrieval systems, vector database architecture, deployment tooling |
Moderate during launch |
|
Operational costs |
Inference traffic, token usage, retrieval pipelines, AI observability |
Scales with product usage |
|
Maintenance costs |
Prompt tuning, workflow updates, reliability testing, orchestration changes |
Grows as workflows expand |
|
Compliance and governance |
Security controls, logging systems, audit workflows |
Depends on industry exposure |
Most founders budget correctly for launch and underestimate what happens after adoption starts. AI operational costs usually emerge from workflow repetition, retrieval depth, orchestration complexity, and production concurrency rather than the initial MVP release itself.
Also Read: How Much Does It Cost to Build an MVP for AI Application?
Inference costs scale through repeated workflow execution, growing context windows, retrieval-heavy prompts, and orchestration layers making multiple model calls behind the scenes.
Many AI MVPs appear financially efficient during early demos because user behavior remains shallow and predictable. Cost patterns usually shift once real customers begin uploading documents, retrying prompts, expanding workflow usage, and interacting with the system continuously.
AI MVPs create operational infrastructure costs that rarely appear in initial project estimates. These costs usually surface after the workflow begins handling production traffic consistently.
The infrastructure footprint of many AI MVPs grows faster than expected because operational reliability requires significantly more supporting systems than the prototype version initially suggested.
AI costs usually scale aggressively when workflows become continuous, retrieval-heavy, or deeply integrated into customer operations.
Internal demos generate predictable traffic. Real customers retry prompts, upload larger datasets, revisit workflows repeatedly, and generate sustained inference volume throughout the day.
As more documents, records, and historical context enter the system, embedding generation, indexing operations, and retrieval overhead expand with them.
Products that initially relied on one model call often evolve into multi-step orchestration pipelines involving classification, retrieval, generation, validation, and formatting stages.
Scheduled processing, autonomous workflows, background summarization, and continuous monitoring pipelines increase inference activity significantly.
Production AI systems gradually add monitoring layers, evaluation pipelines, audit logging, fallback handling, and redundancy controls once operational issues begin appearing under real usage conditions.
Most cost escalation happens gradually. Teams often notice margin pressure only after infrastructure complexity and inference volume have already expanded together.
AI spend stays manageable when product teams delay unnecessary infrastructure complexity and optimize workflows before scaling automation depth.
Early-stage AI infrastructure planning usually benefits more from disciplined workflow design than aggressive model optimization.
Accelerate launch timelines with custom MVP software development built around real production workflows.
Call Our AI ExpertsMost AI MVPs do not require large AI research teams during early-stage development. A small team with strong full-stack engineering capability, practical AI integration experience, and product-level workflow understanding is usually enough to validate the MVP successfully. Team structure during custom AI MVP development should follow workflow complexity, infrastructure requirements, and operational risk instead of broad assumptions about AI hiring needs.
ML engineers become necessary when the AI MVP depends on model customization, retrieval optimization, inference tuning, or production-scale AI infrastructure planning. Many startup-specific AI MVP development projects can reach production validation using hosted APIs and managed orchestration layers without dedicated machine learning teams.
Hiring ML engineers before the workflow stabilizes often slows AI product validation strategy execution because infrastructure complexity grows faster than product learning cycles
Full-stack engineers are usually enough when the AI MVP primarily depends on orchestration, retrieval workflows, API integrations, and product execution rather than custom model development.
Many successful AI MVPs reach production validation using lean engineering teams focused on scalable MVP architecture, AI implementation workflow stability, and operational reliability.
Also Read: The Advantages of Hiring a Full Stack Developer to Develop MVP
AI product thinking matters because AI MVP development succeeds or fails at the workflow level, not at the model level. Teams frequently overfocus on generation quality while underestimating operational friction, user correction behavior, and workflow adoption patterns.
AI MVPs usually break operationally through workflow friction long before the underlying models become the primary limitation.
AI coding assistants help most during rapid implementation, scaffolding, debugging support, documentation generation, and repetitive engineering tasks inside AI MVP development workflows. Human oversight remains critical for architecture planning, workflow reliability, infrastructure decisions, and operational safeguards.
AI-generated implementation usually fails at the orchestration and workflow layer when production traffic, retrieval instability, and operational edge cases begin affecting the MVP under real usage conditions.

The most common AI MVP failure patterns include premature infrastructure complexity, workflow overautomation, weak evaluation systems, demo-driven product design, and treating probabilistic AI behavior like traditional deterministic software. These issues usually appear during early custom AI MVP software development when product assumptions are still evolving but the architecture has already become difficult to change.
Many teams invest in custom model training before validating whether the underlying workflow solves a meaningful operational problem. During early custom AI MVP software development, proprietary model infrastructure introduces training pipelines, inference optimization requirements, AI deployment workflows, and evaluation overhead long before the product itself reaches stable usage patterns.
AI agents frequently become a source of orchestration complexity during MVP development. Teams add autonomous workflows, memory systems, multi-agent coordination, and tool-routing layers before validating whether the workflow requires that level of automation. This usually slows iteration speed and complicates AI workflow design during the stage where rapid product learning matters most.
Many AI MVPs accumulate summarizers, copilots, generators, and automation layers without improving the actual workflow experience for the user. Strong tailored AI MVP development depends more on operational clarity, correction handling, workflow speed, and AI-assisted usability than the number of AI capabilities included inside the product.
AI evaluation infrastructure often gets postponed because the MVP appears functional during controlled testing environments. Once production traffic increases, teams struggle to trace hallucinations, retrieval instability, prompt degradation, or orchestration failures because AI output evaluation systems were never integrated into the AI engineering workflow early enough.
AI MVPs built around polished demos usually fail once real users introduce inconsistent prompts, unpredictable workflow behavior, incomplete context, and sustained usage patterns. Demo environments rarely expose retrieval bottlenecks, operational latency, token consumption management issues, or AI infrastructure planning gaps that emerge under production traffic.
Many startup teams design AI-assisted workflows as if outputs will behave consistently across all production scenarios. In reality, probabilistic software systems require fallback handling, confidence-aware workflow automation, human review checkpoints, and scalable MVP architecture capable of absorbing unreliable or inconsistent generation behavior safely.
|
Failure Pattern |
What Usually Breaks First |
Typical Business Impact |
|---|---|---|
|
Building proprietary models too early |
Iteration speed and engineering focus |
Slower MVP validation and rising infrastructure costs |
|
Overengineering AI agents |
Workflow stability and orchestration reliability |
Delayed launches and operational complexity |
|
Prioritizing features over workflows |
User adoption and retention |
Weak product usage despite strong demos |
|
Ignoring evaluation infrastructure |
Output reliability visibility |
Inability to debug production failures |
|
Designing for demos |
Production scalability and consistency |
Workflow instability under real usage |
|
Treating AI like deterministic software |
Error handling and operational safeguards |
Increased correction overhead and user distrust |
Most scalable AI MVP development failures originate from workflow instability and operational assumptions rather than model capability limitations. Teams building custom AI software development workflows usually gain more long-term reliability from controlled architecture expansion than from early infrastructure sophistication.
The right AI MVP development approach depends on how complex the workflow is expected to become after launch. Early validation workflows can often move quickly with no-code or low-code systems, while retrieval-heavy products, infrastructure-sensitive workflows, and AI-native SaaS platforms usually require custom AI MVP software development much earlier.
No-code is enough when the AI MVP only needs to validate a narrow workflow without deep orchestration, complex backend coordination, or infrastructure-level customization.
Teams validating:
can often launch quickly using managed no-code platforms and hosted AI APIs. This works especially well during early MVP product validation because:
Problems usually appear once the product starts requiring:
At that stage, the platform abstraction layer starts limiting how the workflow evolves operationally.
Low-code AI systems usually break down once workflow orchestration becomes harder to visualize, debug, or scale safely.
|
Workflow Requirement |
What Usually Happens |
|---|---|
|
Simple AI-assisted workflows |
Stable and fast to ship |
|
Basic API orchestration |
Manageable |
|
Retrieval-heavy pipelines |
Increasing workflow fragility |
|
Multi-model coordination |
Difficult to maintain |
|
Advanced AI deployment workflows |
Limited infrastructure control |
|
AI operational monitoring |
Weak observability |
|
High-volume production traffic |
Debugging complexity increases |
The friction rarely appears all at once. Teams typically notice:
Many startups continue extending low-code systems beyond their operational limits because rebuilding the workflow later becomes difficult once customers depend on it.
Custom AI development becomes necessary once the workflow itself turns into the product advantage. That usually happens when the MVP depends on:
Teams building tailored AI MVP development workflows often reach this point after discovering that platform abstractions hide too much operational behavior during production scaling.
Custom AI MVP development also becomes necessary when:
The engineering overhead increases, but operational control improves significantly once the workflow becomes production-critical.
The best approach depends on how much uncertainty still exists around the workflow.
|
Startup Context |
Best-Fit Approach |
|---|---|
|
Fast validation of a narrow AI workflow |
No-code |
|
Early SaaS MVP with moderate orchestration needs |
Low-code |
|
AI-native product with evolving infrastructure needs |
Custom AI MVP development |
|
Retrieval-heavy workflow automation |
Tailored AI application development |
|
Production-sensitive AI workflows |
Custom AI software development |
|
Long-term scalable AI products |
Startup-specific AI software architecture |
Teams building scalable AI MVP development workflows usually benefit from delaying infrastructure complexity until workflow reliability and product usage stabilize under real production conditions.
Use startup-specific MVP software development to validate workflows before investing in heavy infrastructure.
Launch Your AI MVP SmarterAfter launch, the AI MVP enters the stage where infrastructure assumptions, workflow reliability, retrieval behavior, and operational scalability get tested under real usage conditions. Production traffic exposes how the system behaves when users introduce inconsistent prompts, repeated workflows, larger datasets, and unpredictable usage patterns across the product lifecycle.
The most useful AI MVP metrics measure whether the workflow becomes operationally dependable and repeatedly useful under production conditions.
A workflow that users repeatedly trust under time pressure usually reveals more product value than high engagement numbers generated during onboarding or demos.
AI feedback loops improve the MVP by exposing where workflows fail operationally, where retrieval quality weakens, and where users repeatedly compensate for unstable behavior manually.
In mature AI MVPs, product improvement usually comes from reducing workflow friction and correction effort rather than increasing generation complexity.
AI MVP architecture should be rebuilt when the existing system starts slowing deployment speed, increasing operational instability, or limiting workflow scalability under production traffic.
At that point, engineering teams usually spend more effort maintaining workaround logic than improving the actual product workflow.
AI MVP product-market fit becomes visible when customers begin depending on the workflow consistently enough that operational usage stabilizes independently of onboarding support or novelty-driven engagement.
Once customers start reorganizing internal workflows around the product, the MVP has usually crossed beyond experimental usage into operational dependence.
The right AI MVP development partner should understand workflow validation, orchestration trade-offs, infrastructure scalability, and production reliability under real usage conditions. During custom AI MVP software development, weak technical decisions made early often become difficult and expensive to reverse once the product starts scaling.
Founders should focus less on AI buzzwords and more on how the team approaches workflow reliability, architecture flexibility, and operational scaling during MVP development.
Useful questions include:
Teams with real startup-specific MVP software development experience usually explain constraints, trade-offs, and scaling risks clearly without overselling automation complexity.
Certain proposal patterns usually indicate that the team is optimizing for presentation quality rather than production durability.
|
Proposal Pattern |
What It Usually Indicates |
|---|---|
|
Custom model training proposed immediately |
Weak workflow validation discipline |
|
No evaluation infrastructure mentioned |
Reliability strategy is incomplete |
|
Heavy focus on autonomous AI agents |
Orchestration complexity may be excessive |
|
Unrealistic delivery timelines |
Operational scope likely underestimated |
|
No discussion of monitoring systems |
Production observability gaps |
|
Tight platform-specific dependencies |
Long-term infrastructure rigidity |
Many proposals look technically impressive during the sales process and then become difficult to maintain once orchestration complexity starts expanding under real usage conditions.
Non-technical founders can evaluate technical depth by listening for operational reasoning instead of tool-heavy explanations.
Strong teams usually explain fallback handling, retrieval instability, retry behavior, and workflow recovery paths clearly.
Experienced partners discuss AI scalability planning, orchestration growth, and infrastructure evolution realistically instead of presenting the MVP as a fixed system.
Teams experienced in tailored AI MVP development usually avoid unnecessary infrastructure complexity during workflow validation stages.
Operationally mature teams naturally discuss AI observability, output evaluation systems, and monitoring workflows.
Technical depth becomes visible when the discussion shifts from AI tooling toward production behavior and operational constraints.
AI architecture experience matters because AI MVP infrastructure evolves continuously after launch. Retrieval systems, orchestration layers, prompt routing, inference coordination, and deployment workflows all become harder to modify once production workflows depend on them.
Teams working with a strong custom software development company usually design:
Architecture mistakes inside AI MVP development rarely fail immediately. Most become visible later through rising inference costs, unstable orchestration behavior, workflow debugging difficulty, or infrastructure bottlenecks under production traffic.
The strongest AI MVP development strategies optimize for fast workflow learning while keeping future infrastructure decisions reversible.
|
Area |
Early MVP Priority |
Scaling Priority |
|---|---|---|
|
Workflow development |
Fast validation cycles |
Operational reliability |
|
AI infrastructure planning |
Managed APIs and hosted tooling |
Cost control and flexibility |
|
Retrieval systems |
Lightweight orchestration |
Performance optimization |
|
AI software deployment workflow |
Rapid iteration |
Stability and rollback safety |
|
AI integration strategy |
Replaceable components |
Infrastructure efficiency |
Teams building bespoke AI workflow development systems usually maintain velocity longer when orchestration layers stay modular and operational scope expands gradually alongside validated production usage.
From retrieval systems to orchestration layers, our AI MVP development services help startups scale with confidence.
Talk to the AI Team at Biz4Group LLCAI MVP architecture is moving toward modular orchestration, workflow-specific infrastructure, smaller inference layers, and tighter operational visibility across production systems. Over the next three years, custom AI MVP software development will focus less on generalized AI capability and more on building efficient, maintainable workflows that can scale reliably under production usage.
AI-native workflows are changing MVP architecture because workflow execution increasingly depends on retrieval behavior, orchestration logic, and real-time inference coordination rather than fixed application flows.
Teams building AI-native products are spending more engineering effort on workflow coordination and operational reliability than on traditional feature expansion.
Smaller task-specific models are becoming more useful because they improve inference efficiency inside production AI MVPs without requiring oversized infrastructure for every workflow.
This shift is making scalable AI MVP development financially easier for startups handling repeated operational workflows at production scale.
AI orchestration layers are evolving into workflow coordination systems responsible for retrieval logic, model routing, state handling, evaluation pipelines, and operational visibility across the AI application stack.
Most AI MVPs still operate more reliably with constrained orchestration workflows than with fully autonomous multi-agent behavior.
On-device AI and edge inference will change how startups approach latency-sensitive workflows, infrastructure cost planning, and privacy-sensitive product design.
Edge inference also changes how AI infrastructure planning works because orchestration logic must coordinate behavior across distributed execution environments instead of one centralized inference layer.
Biz4Group LLC is an AI development company experienced in custom AI MVP software development for startups and enterprises building AI-native products, workflow automation systems, and scalable SaaS platforms. The team focuses on startup-specific AI MVP development that balances rapid product validation, scalable architecture planning, AI infrastructure flexibility, and long-term operational maintainability from the earliest stages of development.
Projects like Truman, Coach AI, Homer AI, Stratum 9 InnerView, CogniHelp, and Insurance AI involved very different AI implementation workflows, ranging from conversational AI and healthcare assistance to recruitment intelligence and AI-assisted learning systems. Across these products, the recurring challenge was not model access alone, but building tailored AI MVP development workflows that could remain reliable, observable, and scalable under real production usage.
What strengthens Biz4Group LLC’s custom AI product development approach:
The development process stays centered around workflow usability, scalable orchestration, operational clarity, and AI product lifecycle adaptability so the MVP can evolve into a production-ready platform without requiring major architectural rewrites after launch.
AI MVP development becomes difficult when teams treat the MVP like a finished AI platform instead of a controlled product validation system. Most early-stage failures come from expanding orchestration complexity, automation depth, and infrastructure scope before the workflow proves operationally useful under real usage conditions.
Strong AI MVPs usually share a few traits: narrow workflow scope, fast iteration cycles, measurable output evaluation, modular infrastructure, and architecture that remains easy to modify after launch. Teams that validate workflow behavior early tend to make better decisions around retrieval systems, orchestration layers, inference scaling, and long-term AI infrastructure planning later.
Custom AI MVP software development also changes how technical trade-offs should be approached. During the MVP stage, speed matters, but replaceability matters more. Workflow visibility matters more than aggressive automation. Operational reliability matters more than adding additional AI features that users may never consistently adopt.
For startups building AI-native SaaS products, retrieval-driven platforms, or AI-assisted operational workflows, partnering with an experienced AI app development company can reduce avoidable architecture mistakes during the stages where product assumptions are still evolving fastest.
Planning Custom AI MVP Development for Your Startup? Reach out to our AI Experts!
Most AI MVPs take between 5 and 7 weeks depending on workflow complexity, retrieval requirements, integrations, and evaluation needs. AI-assisted SaaS workflows using existing APIs can move faster, while products requiring custom orchestration, compliance controls, or complex AI infrastructure planning usually take longer.
Custom AI MVP software development usually costs between $10,000 and $100,000. The range depends on workflow complexity, AI model development, retrieval systems, integrations, UI/UX scope, and infrastructure requirements. MVPs using managed AI APIs and lightweight orchestration are generally less expensive than products requiring custom AI architecture, scalable inference pipelines, or production-grade observability.
Yes. Most AI MVPs do not require custom model training initially. Many startups validate their products successfully using existing large language model APIs, retrieval systems, prompt orchestration, and workflow automation layers before investing in proprietary AI infrastructure or fine-tuning pipelines.
AI MVP development works best for products where automation, contextual decision-making, document handling, conversational workflows, search enhancement, or operational assistance create measurable workflow improvements. Products without recurring workflow value or usable data structures often struggle to justify AI infrastructure complexity during the MVP stage.
Yes. AI MVPs require continuous monitoring, retrieval optimization, prompt refinement, infrastructure scaling, and output evaluation after launch. Unlike traditional software systems, AI-assisted workflows evolve based on production usage patterns, changing datasets, and operational feedback loops.
An AI MVP is usually ready to scale when workflow usage becomes repeatable, output correction rates stabilize, infrastructure behavior becomes predictable under production traffic, and customers begin depending on the product operationally instead of using it experimentally.

with Biz4Group today!
Our website require some cookies to function properly. Read our privacy policy to know more.